爬取中国政府采购网的案例。
-
查看数据,构建基本框架
首先先打开网页看看我们需要爬什么样的数据:
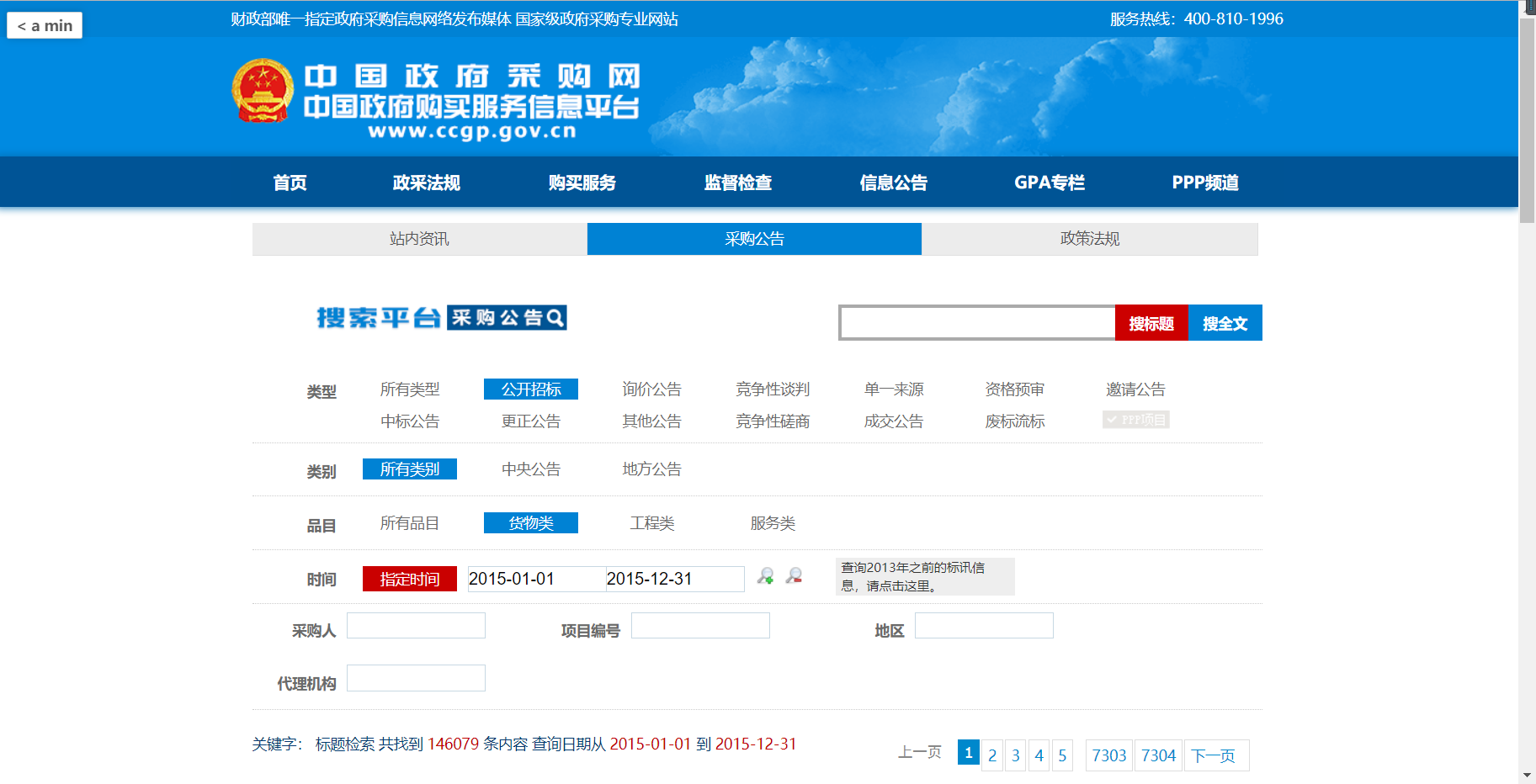
往下滑就可以看到我们需要的数据是长什么样子的啦!

我们要做的就是将所有数据以品目、类别为索引进行查找数据,并将其从网页上爬下存在本地数据库中。
-
观察链接,拼接出所有网址
链接 含义 http://search.ccgp.gov.cn/bxsearch?searchtype=1主页面的网址,子页面的开头都是这样,不会变动 &page_index=1此参数是代表当前页数,从1开始 &bidSort=0&buyerName=&projectId=其他参数,在后续进行拼接网址时不进行更改 &pinMu=1品目的选项,1货物类;2工程类;3服务类 &bidType=1招标类型,1 –公开招标; 2–询价公告;…. &dbselect=bidx&kw=固定不变的 &start_time=2015%3A01%3A01这里是开始的时间 &end_time=2015%3A12%3A31这里是结束的时间 &timeType=6如果需要自定义开始结束时间,这里的参数填6 &displayZone=&zoneId=&pppStatus=0&agentName=固定不变的 此时代码的大致框架就已经形成了,构造一个三层的嵌套循环,最内一层则是页数的变换,即是更改&page_index=后的数字,中间一层循环和最外层循环则是品目和类别。(位置可以颠倒)
-
访问网址,获取到网址内容
接下来定义了一些关于拼接网址的参数:

创建和数据库的连接,由于小编要将爬取到的数据存储在MySQL数据库中,所以需要提前创建连接,以便后续的存储:
先将第二步的三层嵌套循环的框架搭好。紧接着完成最重要的一步:将要访问的网址拼接好。如下图所示,小编改变了“&page_index=”、“&pinMu=”、“&bidType=”、“&start_time=”以及“&end_time=”这五个参数。这5个参数分别是控制当前所在页、品目、公告类型、开始时间、结束时间等功能。拼接之后便用requests进行访问网页,BeatifulSoup美化源码结构。

-
解析获取的文本
上述代码获取到的内容的部分截图如下:

你可以看到在第一步中展示的待爬取信息现在已经转变为本地文本,由于抓取下的数据是整个网页的源码,里面含有大量我们并不需要的信息,因此小编接下来做的事就是提取自己需要的信息。例如标题、时间等信息都是小编需要的信息。下面详细讲解如何获取到标题,其他字段抓取都可以照猫画虎了。
打开其中一个网址,按下F12,跟着下面箭头顺序点击;这时右侧的网页源码有一处会用蓝色高亮显示,这个就是对应刚刚点击标题的源码。
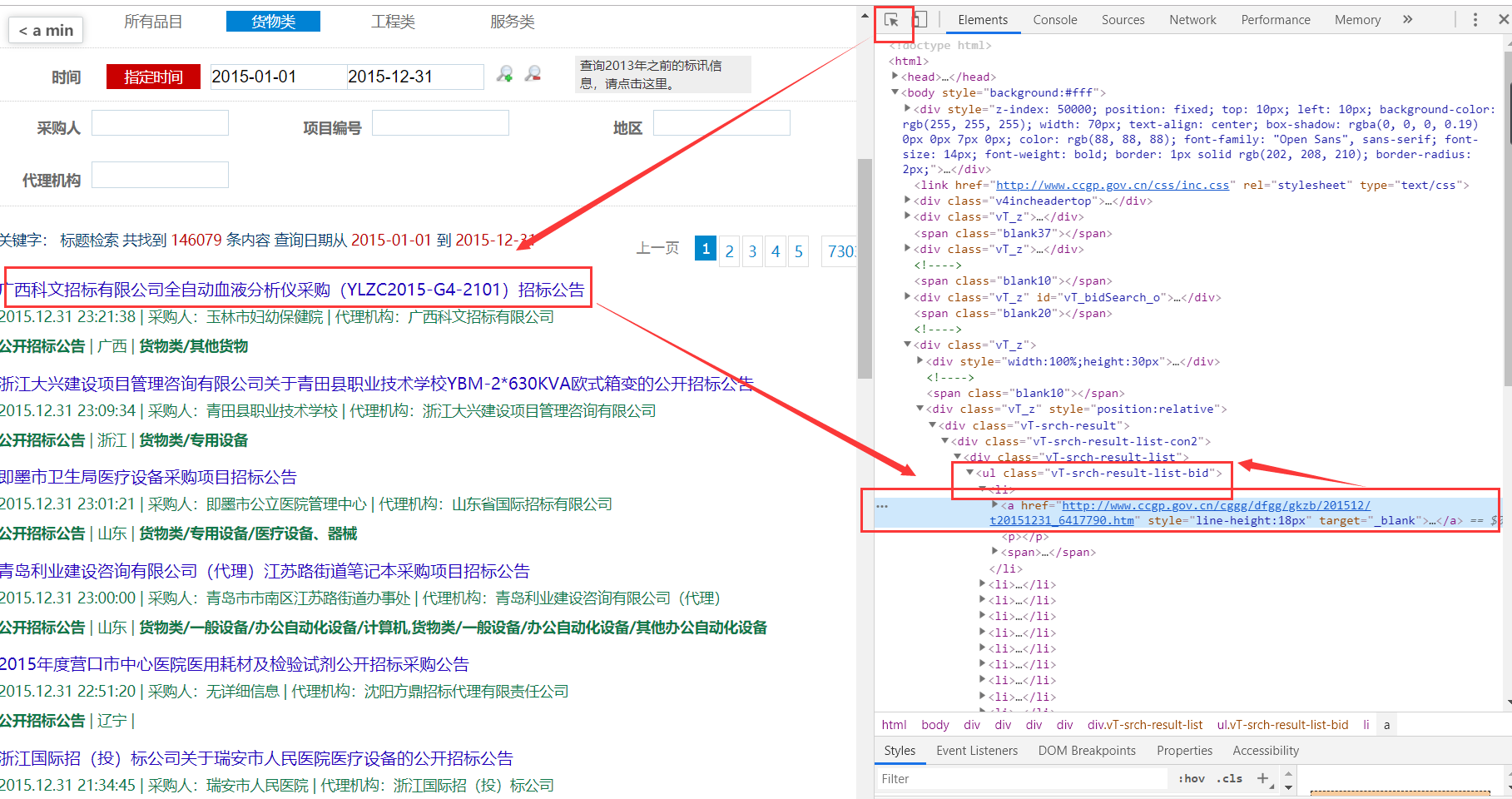
打开a标签,会发现我们需要的标题内容就在这个标签下,仔细观察标签的位置,可以看到标题在一个class= vT-srch-result-list-bid的ul标签下,进一步是一个li标签,最后在li标签的a标签下。
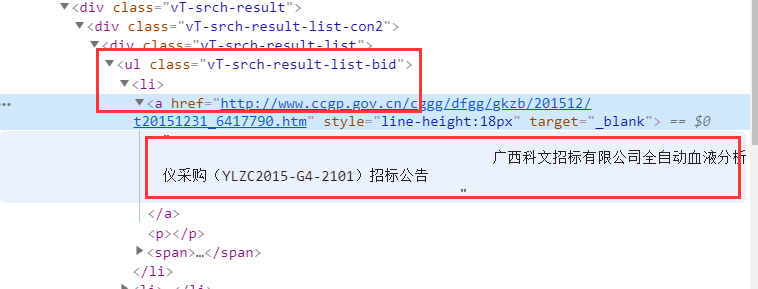
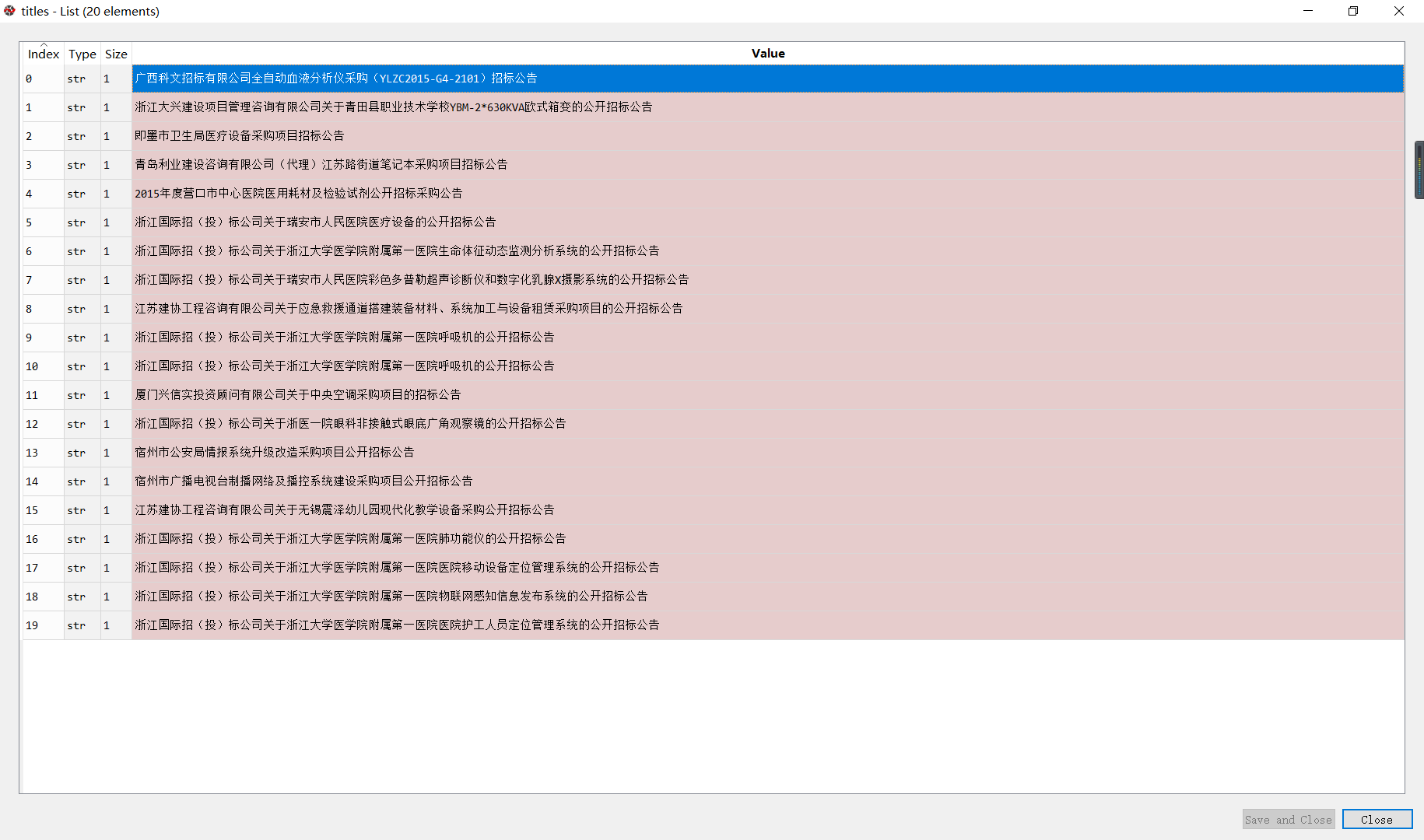
根据上述我们找到的关系,利用select函数即可获取到指定标签下的文本内容,代码如下: title = soup.select(‘.vT-srch-result-list-bid li > a’) 这时title里存储的是Tag类型的数据,无法看到其中的内容,用下述代码即可将title转化为文本:titles = [tle.text.strip() for tle in title]得到的内容如下所示:
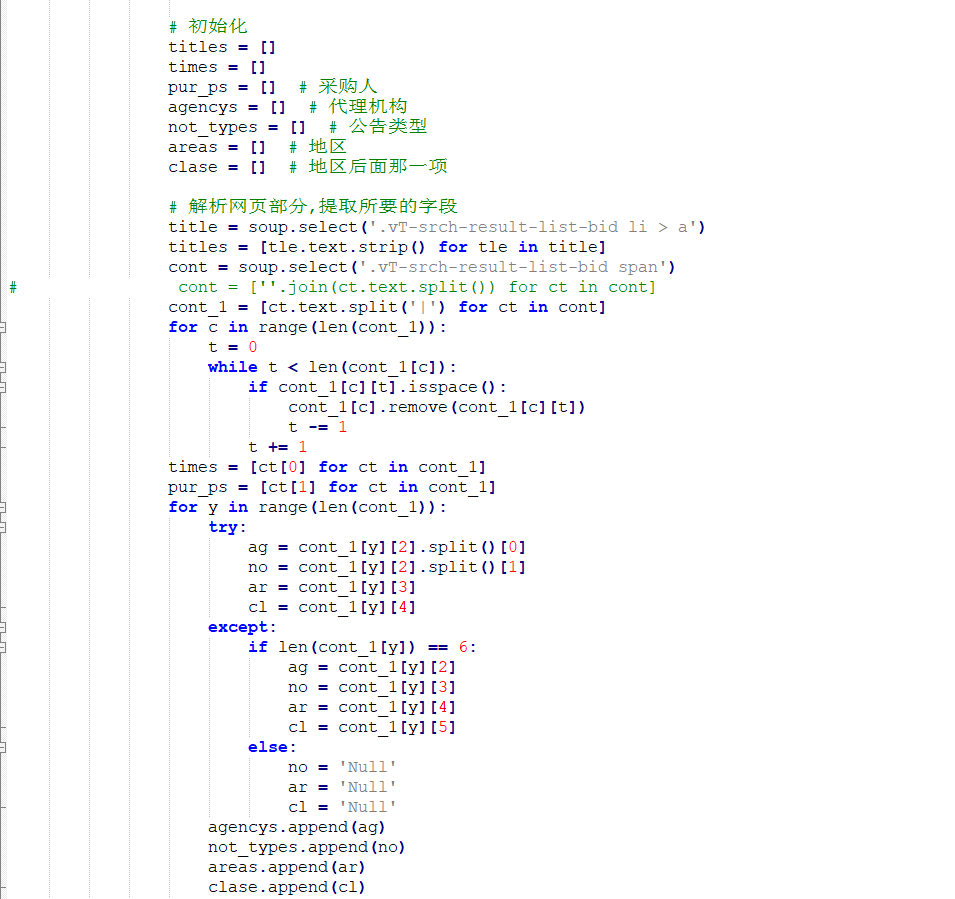
接下来就是获取自己想要的字段了。以下是我的代码,仅供参考,可以根据自己的需求来设计代码。
还缺一个中止翻页的代码:

这部分代码就是判断网页是否循环到了尾页。
-
存入数据
这部分代码实现的功能就是连接外部数据库,将数据存储在数据库中。我用的MySQL数据库哦~

这两天收到写一篇关于分析这个案例文章的任务,花了一阵功夫写的,想着不能浪费了,就放在了自己的博客上。
完整代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 22 13:41:11 2019
@author: Nora
"""
from urllib import request
from bs4 import BeautifulSoup
import pymysql
import requests
import time
start_list=['2015%3A01%3A01','2016%3A01%3A01','2017%3A01%3A01','2018%3A01%3A01']
end_list=['2015%3A12%3A31','2016%3A12%3A31','2017%3A12%3A31','2018%3A12%3A31']
time_data=['2015','2016','2017','2018']
pinmu_data = ['货物类','工程类','服务类']
page404 = """
<!-- Page Header -->
<header class="intro-header" style="background-image: url('{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}')">
<div class="container">
<div class="row">
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1">
<div class="site-heading" id="tag-heading">
<h1>404</h1>
<span class="subheading">{{ page.description }}</span>
</div>
</div>
</div>
</div>
</header>
<script>
document.body.classList.add('page-fullscreen');
</script>
"""
i = 0 ### 年份 2015-2018, 对应于0-3
dbconn=pymysql.connect(
host="localhost",
database="bid_notice_info",
password="123456",
user="root",
port=3306,
charset='utf8mb4'
)
import os
import hashlib
def md5Encode(img):
m = hashlib.md5()
m.update(img.encode("utf8"))
return m.hexdigest()
for j in range(1,13):
'''
类型的循环,1-12 一共12种类型
'''
for k in range(1,4):
'''
品目的循环,1-3,一共3种品目
'''
a=1
z=0
titles = [1]
cur=dbconn.cursor()
while a:
'''
页数的循环,停止条件是判断下一页的链接是否为空
'''
try:
url = 'http://search.ccgp.gov.cn/bxsearch?searchtype=1&page_index='+str(a)+\
'&bidSort=0&buyerName=&projectId=&pinMu='+str(k)+'&bidType='+str(j)+'&dbselect=bidx&kw=&start_time='\
+start_list[i]+'&end_time='+end_list[i]+'&timeType=6&displayZone=&zoneId=&pppStatus=0&agentName='
# 获取网页部分
content = requests.get(url).text
soup = BeautifulSoup(content, 'html.parser')
# 判断是否终止翻页循环
if soup.select('.vT-srch-result-list-bid li > a')[-1].text.strip() == titles[-1]:
# a=0
if soup.select('.vT-srch-result-list-bid li > a')[-1].text.strip() == titles[-1]:
break
a += 1
continue
if z!= 0:
print('==========报错已恢复=========')
z = 0
# 初始化
titles = []
times = []
pur_ps = [] # 采购人
agencys = [] # 代理机构
not_types = [] # 公告类型
areas = [] # 地区
clase = [] # 地区后面那一项
# 解析网页部分,提取所要的字段
title = soup.select('.vT-srch-result-list-bid li > a')
titles = [tle.text.strip() for tle in title]
cont = soup.select('.vT-srch-result-list-bid span')
# cont = [''.join(ct.text.split()) for ct in cont]
cont_1 = [ct.text.split('|') for ct in cont]
for c in range(len(cont_1)):
t = 0
while t < len(cont_1[c]):
if cont_1[c][t].isspace():
cont_1[c].remove(cont_1[c][t])
t -= 1
t += 1
times = [ct[0] for ct in cont_1]
pur_ps = [ct[1] for ct in cont_1]
for y in range(len(cont_1)):
try:
ag = cont_1[y][2].split()[0]
no = cont_1[y][2].split()[1]
ar = cont_1[y][3]
cl = cont_1[y][4]
except:
if len(cont_1[y]) == 6:
ag = cont_1[y][2]
no = cont_1[y][3]
ar = cont_1[y][4]
cl = cont_1[y][5]
else:
no = 'Null'
ar = 'Null'
cl = 'Null'
agencys.append(ag)
not_types.append(no)
areas.append(ar)
clase.append(cl)
# agencys = [ct[2].split()[0] for ct in cont_1]
# not_types = [ct[2].split()[1] for ct in cont_1]
# try:
# areas = [ct[3] for ct in cont_1]
# except:
# areas = ['Null'] * len(cont_1)
# try:
# clase = [ct[4] for ct in cont_1]
# except:
# clase = ['Null'] * len(cont_1)
year = time_data[i]
for r in range(len(title)):
'''
逐条存储到数据库
'''
times_nd=times[r].split(' ')[0].replace('.','-')
pur_ps_nd=pur_ps[r].split('\r')[0]
areas_nd=areas[r].split('\r')[0]
clase_nd=clase[r].replace('\n','')
get_url=title[r].get('href')
try:
md5ss=md5Encode(titles[r])
cur.execute("INSERT INTO bid_not(`titles`,`years`,`pinmu_id`,`times`,`pur_ps`,`agencys`,`not_types`,`areas`,`clase`,`url`,`md5`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (titles[r],year,k,times_nd,pur_ps_nd,agencys[r],not_types[r],areas_nd,clase_nd,get_url,md5ss))
except Exception as e:
if '1366' in str(e):
titles[r] = titles[r].split('公告')[0] + '公告'
md5ss=md5Encode(titles[r])
cur.execute("INSERT INTO bid_not(`titles`,`years`,`pinmu_id`,`times`,`pur_ps`,`agencys`,`not_types`,`areas`,`clase`,`url`,`md5`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)", (titles[r],year,k,times_nd,pur_ps_nd,agencys[r],not_types[r],areas_nd,clase_nd,get_url,md5ss))
dbconn.commit()
try:
aaaa=requests.get(get_url,timeout=30)
aaaa.encoding = 'utf-8'
aaaa=aaaa.text
except:
aaaa = page404
local_main='D:/zhongguoxxx/'+time_data[i]+'/'+str(j)+'/'+str(k)+'/'+times_nd+'/'
if not (os.path.exists(local_main)):
os.makedirs(local_main)
with open(local_main+md5ss+'.html','w',encoding='utf-8') as f:
f.write(aaaa)
f.close()
# 增加页数
a += 1
print(a)
except:
z += 1
print('============第{}次报错,等待中=============='.format(z))
# 5次请求失败则终止程序
if z >= 2:
print('================程序异常,退出===============')
os.system('python error_email.py')
a += 1
continue
# 一次请求失败则暂停2min,等待IP恢复
time.sleep(120)
continue
print('这是类型{} 品目{} ,一共有{}页'.format(j, k, a))
os.system('python send_email.py')
cur.close()
注:在这个代码中我加了一些其他辅助代码,例如加了一个自动发邮件功能,想要什么功能可以自己加。