在看《Python数据可视化编程实战(第2版)》这本书的时候,看到第二章里面读取数据的方法总结了一下,感觉还不错就打算记录下来。
其中包括csv文件、excel文件、定宽文件、制表符文件、数据库文件以及利用pandas读取文件。
从CSV文件导入数据
CSV格式的文件是指逗号分隔的值(文件中还包括一个文件头,也是以逗号分隔的)。
读取步骤:
- 打开文件;
- 首先读取文件头;
- 然后读取剩余行;
- 当发生错误时抛出异常;
- 读取完所有内容后,打印文件头和其余所有行。
文件内容如下:
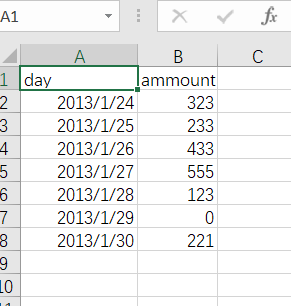
实现代码如下:
import csv
import sys
filename = 'ch02-data.csv'
data = []
try:
with open(filename) as f:
reader = csv.reader(f)
c = 0
for row in reader:
if c == 0:
header = row
else:
data.append(row)
c += 1
except csv.Error as e:
print("Error reading CSV file at line %s: %s" % (reader.line_num, e))
sys.exit(-1)
if header:
print(header)
print('==================')
for datarow in data:
print(datarow)
[out]:
['day', 'ammount']
==================
['2013-01-24', '323']
['2013-01-25', '233']
['2013-01-26', '433']
['2013-01-27', '555']
['2013-01-28', '123']
['2013-01-29', '0']
['2013-01-30', '221']
如果想要了解csv模块的来龙去脉,可以看PEP文档中的《CSV文件API》。
如果想要加载大数据文件,应该使用Numpy库中的loadtxt()方法,这个方法可以很好的处理CSV大数据文件。
numpy.loadtxt()方法比类似的 numpy.genfromtxt()方法要快一些,但是后者能更好的处理缺失数据,而且在处理已加载文件的某些列时,可以使用一些方法来做些额外的事情。
从Microsoft Excel文件导入数据
python也可以直接读取xlsx文件,读取该类型文件将使用xlrd模块,可使用pip进行安装模块:
pip install xlrd
操作步骤:
- 打开文件的工作簿;
- 根据名称找到工作表;
- 根据函数(nrows)和列数(ncols)读取单元格的内容;
- 因为只是用做演示,本例仅打印出了读取的数据集合;
文件内容如下:

实现代码如下:
import xlrd
from xlrd.xldate import XLDateAmbiguous
file = 'ch02-xlsxdata.xlsx'
wb = xlrd.open_workbook(filename=file)
ws = wb.sheet_by_name('Sheet1')
dataset = []
for r in range(ws.nrows):
col = []
for c in range(ws.ncols):
col.append(ws.cell(r, c).value)
if ws.cell_type(r, c) == xlrd.XL_CELL_DATE:
try:
print(ws.cell_type(r, c))
from datetime import datetime
date_value = xlrd.xldate_as_tuple(ws.cell(r, c).value, wb.datemode)
print(datetime(*date_value))
except XLDateAmbiguous as e:
print(e)
dataset.append(col)
from pprint import pprint
pprint(dataset)
[out]:
3
1.25
[[28.0,
65.0,
'0.833730025131149-0.988897705762865i',
'3.85373803791938-27.0168132580039i',
120.0,
0.23,
72.0,
9.0,
1.4000000000000001,
1.25,
6.023029280112979,
3.141,
'CDXCIX',
1.22514845490862e-16,
1.7724538509055159,
0.8427007351745552],
[4.0,
0.8427007351745552,
'5+12i',
'1.09868411346781+0.455089860562227i',
1.0,
1.0,
3402.0,
-9.0,
2.0,
380.8865742483644,
5.0,
-3.1,
'LDVLIV',
1.0,
2.5066282746310002,
0.0],
[97.0,
0.15729926482544476,
'1.46869393991589+2.28735528717884i',
'8+i',
1.0,
12.0,
0.9999999999999998,
1259.999999999999,
4.0,
761.7731484967288,
0.0,
31400.0,
'XDIX',
0.49999999999999994,
5.0,
101.98166642847517],
[0.981666428475166,
1.0,
'0.346573590279973+0.785398163397448i',
'8+i',
1.0,
1.0,
-3.0,
3.0,
2.0,
380.8865742483644,
2.2,
4.0,
'VDIV',
0.49999999999999994,
21.0,
''],
[0.2773878036322587,
1.0,
'0.150514997831991+0.34109408846046i',
0.24,
48.0,
5.0,
-0.3333333333333333,
3.0,
-2.0,
2.0,
2.1,
77.0,
'ID',
1.1752011936438014,
101.98166642847517,
''],
[23.0,
13.0,
'0.500000000038482+1.13309003554401i',
28.0,
105.0,
8.0,
1.9999999999999998,
3.0,
3.141592653589793,
1.0,
-1.48,
3.142,
'MMXIII',
-1.1752011936438014,
116.98166642847517,
''],
['10111',
-1.0,
'-46+9.00000000000001i',
65.0,
-2.0,
-9.0,
18.0,
-1.0,
25.0,
-3.0,
20.0,
-3.2,
1.0,
0.10104906311828733,
25.27738780363226,
''],
['1+i',
0.9272952180016122,
'30+60i',
-2.0,
2.0,
0.0,
10.0,
-3.0,
2401077.2220695755,
4.71238898038469,
3.0,
31500.0,
0.0,
4.0,
1.0,
''],
[65.0,
'3-4i',
6.0,
7.38905609893065,
1.5,
10.0,
1.0,
-9.0,
5.656854249492381,
0.2808203258233153,
76.0,
1593.0,
-1.0,
2.0,
101.0,
'']]
工作原理:
在最上层是一个包含一个或多个工作表(xlrd.sheet.Sheet)的工作簿(Python类xlrd.book.Book)。每个工作表有一个单元格对象(xlrd.sheet.Cell),我们能从单元格中将值读取出来。
通过调用open_workbook()方法,我们从文件中加载了一个工作簿,并返回一个xlrd.book实例。Book实例包含了一个工作簿的所有信息,如工作表单。通过调用sheet_by_name()方法可以访问指定的工作表,如果需要所有的工作表,可以调用sheets()方法。sheets()方法返回一个xlrx.sheet.Sheet实例的列表。xlrx.sheet.Sheet类有行和列属性,我们能通过这些属性来指定循环的范围,并通过调用cell()方法来访问工作表中的每个特定的单元格。虽然有一个xlrx.sheet.Cell类,但并不需要直接使用它。
日期是以浮点数而不是以某个日期类型存储的。但是,xlrd模块有能力检查数据的值,并推断出数据值实际上是否为一个日期。这样,我们就能通过检查单元格类型来得到Python data对象。如果数字的字符串像日期,xlrd模块将返回xlrd.XL_CELL_DATE作为单元格类型。
xlrd模块的一个非常好的特性是它能按照需要仅加载文件的部分内容到内存中。open_wordbook方法有一个on_demand参数,在调用时把它置为True,工作表就能按需加载了。例如:
book = open_workbook('large.xls', on_demand=True)
Excel文件的写操作用xlwt模块来完成。
从定宽数据文件导入数据
事件的日志文件和基于时间序列的文件是数据可视化中最常见的数据源。可用CSV读取方式进行读取,Python中的struct模块能提升性能,因为这个模块是用C语言而不是Python实现的。
实现步骤如下:
- 指定要读取的数据文件;
- 定义数据读取的方式;
- 逐行读取文件并根据格式把每行解析成单独的数据字段;
- 按单独数据字段的形式打印每一行。
实现代码如下:
import struct
import string
mask='9s14s5s'
parse = struct.Struct(mask).unpack_from
print('formatstring {!r}, record size: {}'.format(\
mask, struct.calcsize(mask)))
datafile = 'ch02-fixed-width-1M.data'
with open(datafile, 'r') as f:
for line in f:
fields = parse(line)
print('fields: ', [field.strip() for field in fields])
工作原理:
我们按照在数据文件中看到的格式定义格式掩码。可以用head、more或者类似的Linux Shell命令来查看文件内容。
字符串格式用来定义要提取的数据的期望显示格式。我们用格式字符定义数据类型。因此,如果掩码定义为9s15s5s,我们可以读作“9个字符宽度的字符串,跟着一个15个字符宽度的字符串,再跟上一个5个字符宽度的字符串”。
一般来说,c定义为字符(char类型)或者长度为1的字符串,s定义为字符串(char[]类型),d定义为浮点数(double类型),以此类推。
然后逐行读取文件内容,并通过unpack_from方法按照定义的格式解析每一行。因为在字段前面(或者后面)可能有多余的空格,用strip()方法可以去掉每个字段的前面以及后面的空格。
对于解包,可以使用struct.Struct类的面向对象(object-oriented,OO)的方式,但也可以像下面的代码这样使用非面向对象的方式:
fields = struct.unpack_from(mask, line)
两种方式唯一的不同是使用的模式。如果想用相同的格式化掩码执行更多的操作,面向对象的方法可以不必在每次调用时声明格式。而且,在将来我们可以继承struct.Struct类,为特定需求进行扩展或者提供额外的功能。
从制表符分隔的文件导入数据
另一种常见的平坦数据文件(flat datafile)格式是制表符分隔的文件。它可能导出自Excel文件,也可能是一些定制软件的输出。
通常我们可以按与CSV文件几乎相同的方式来读取这种格式的文件内容。因为Python的csv模块能够让我们用相同的原则来读取相似文件格式的变体——其中一种就是制表符分割格式。
实现代码如下:
import csv
import sys
filename = 'ch02-data.tab'
data = []
try:
with open(filename) as f:
reader = csv.reader(f, dialect=csv.excel_tab)
c = 0
for row in reader:
if c == 0:
header = row
else:
data.append(row)
c += 1
except csv.Error as e:
print("Error reading CSV file at line %s: %s" % (reader.line_num, e))
sys.exit(-1)
if header:
print(header)
print('===================')
for datarow in data:
print(datarow)
[out]:
['day "ammount"']
===================
['2013-01-24 323']
['2013-01-25 233']
['2013-01-26 433']
['2013-01-27 555']
['2013-01-28 123']
['2013-01-29 0']
['2013-01-30 221']
工作原理:
指定dialect参数为excel_tab。
基于CSV格式读取数据的方式没有办法处理有“脏数据”的情况,下面的代码在读取文件数据时对“脏数据”进行了清理:
datafile = 'ch02-data-dirty.tab'
with open(datafile, 'r') as f:
for line in f:
# remove next comment to see line before cleanup
# print 'DIRTY: ', line.split('\t')
# we remove any space in line start or end
line = line.strip()
# now we split the line by tab delimiter
print line.split('\t')
[out]:
['"day" "ammount"']
['2013-01-24 323']
['2013-01-25 233']
['2013-01-26 433']
['2013-01-27 555']
['2013-01-28 123']
['2013-01-29 0']
['2013-01-30 221']
关于如何检测格式,可以根据文件扩展名(.csv & .tab)或者其他的方法(eg:csv.Sniffer类)来判断。
从JSON数据源导入数据
JavaScript Object Notation(JSON)作为一种平台无关的格式被广泛地应用于系统间或者应用间的数据交换。
资源是我们可以读取的任何东西,可以是一个文件或者一个URL端点(可以是远程进程/程序的输出,或者一个远程静态文件)。
需要requests模块。
实现步骤如下:
- 指定GitHub URL来读取JSON格式数据;
- 使用requests模块访问指定的URL并获取内容;
- 读取内容并将之转化为JSON格式的对象。
import requests
from pprint import pprint
url = 'https://api.github.com/users/justglowing'
r = requests.get(url)
json_obj = r.json()
pprint(json_obj)
[out]:
{'avatar_url': 'https://avatars2.githubusercontent.com/u/4929177?v=4',
'bio': 'Data Scientist, teaching fellow, Python enthusiast, fearless '
'visionarist, lateral thinker.',
'blog': 'http://glowingpython.blogspot.com/',
'company': None,
'created_at': '2013-07-03T10:07:22Z',
'email': None,
'events_url': 'https://api.github.com/users/JustGlowing/events{/privacy}',
'followers': 44,
'followers_url': 'https://api.github.com/users/JustGlowing/followers',
'following': 4,
'following_url': 'https://api.github.com/users/JustGlowing/following{/other_user}',
'gists_url': 'https://api.github.com/users/JustGlowing/gists{/gist_id}',
'gravatar_id': '',
'hireable': None,
'html_url': 'https://github.com/JustGlowing',
'id': 4929177,
'location': 'Cambridge, UK',
'login': 'JustGlowing',
'name': 'Giuseppe Vettigli',
'node_id': 'MDQ6VXNlcjQ5MjkxNzc=',
'organizations_url': 'https://api.github.com/users/JustGlowing/orgs',
'public_gists': 6,
'public_repos': 7,
'received_events_url': 'https://api.github.com/users/JustGlowing/received_events',
'repos_url': 'https://api.github.com/users/JustGlowing/repos',
'site_admin': False,
'starred_url': 'https://api.github.com/users/JustGlowing/starred{/owner}{/repo}',
'subscriptions_url': 'https://api.github.com/users/JustGlowing/subscriptions',
'type': 'User',
'updated_at': '2019-09-18T13:38:03Z',
'url': 'https://api.github.com/users/JustGlowing'}
工作原理:
首先用requests模块或缺远程资源,获取到数据和请求元数据后,把他们封装到Response对象。利用Response.json()方法,这个方法可以读取Response.content的内容,按照JSON格式解析并加载到JSON对象中。
接下来处理数据,wget或curl可打开并检查数据。
或者在IPython中获取数据,并以交互的方式查看输出。在IPython中用命令%run program_name.py运行程序。执行完毕后会得到程序生成的所有变量,可以使用%who或者%whos把它们列出来。
jstring = '{"name": "prod1", "price": 12.50}'
import json
from decimal import Decimal
json.loads(jstring, parse_float=Decimal)
[out]:
{'name': 'prod1', 'price': Decimal('12.50')}
用Pandas导入和操作数据
import pandas as pd
data = pd.read_csv('ch02-data.csv')
data['amount_x_2'] = data['ammount']*2
data.to_csv('ch02-data_more.csv')
print(data.ammount)
[out]:
0 323
1 233
2 433
3 555
4 123
5 0
6 221
Name: ammount, dtype: int64
pd.read_csv('ch02-data.tab', skiprows=1, delimiter=' *', names=['day','amount'])
[out]:
day amount
0 2013-01-24 323
1 2013-01-25 233
2 2013-01-26 433
3 2013-01-27 555
4 2013-01-28 123
5 2013-01-29 0
6 2013-01-30 221
print(data.shape)
[out]:
(7, 3)
pandas.read_csv()方法有许多参数,例如如果文件中的值是按照空格而不是逗号分隔的,可以使用delimiter参数正确的解析数据。下面代码的例子中使用的文件数据是由不定数量的空格分隔的,还指定了文件头:
pd.read_csv('ch02-data.tab', skiprows=1, delimiter=' *', names=['day', 'amount'])
从数据库导入数据
这里展示在Python中如何使用SQL drivers访问数据。
操作步骤如下:
- 连接数据库引擎(或者是SQLite文件);
- 在选择的表上执行查询操作;
- 读取从数据库引擎返回的结果。
示例代码如下:
% a.py
import sqlite3
import sys
if len(sys.argv) < 2:
print("Error: You must supply at least SQL script.")
print("Usage: %s table.db ./sql-dump.sql" % (sys.argv[0]))
sys.exit(1)
script_path = sys.argv[1]
if len(sys.argv) == 3:
db = sys.argv[2]
else:
# if DB is not defined
# create memory database
db = ":memory:"
try:
con = sqlite3.connect(db)
with con:
cur = con.cursor()
with open(script_path,'rb') as f:
cur.executescript(f.read())
except sqlite3.Error as err:
print("Error occured: %s" % err)
在把数据导入到数据库之后,就能查询数据并进行一些操作了。一下是哦那个书库文件读取数据的代码。
% b.py
import sqlite3
import sys
if len(sys.argv) != 2:
print("Please specify database file.")
sys.exit(1)
db = sys.argv[1]
try:
con = sqlite3.connect(db)
with con:
cur = con.cursor()
query = 'SELECT ID, Name, Population FROM City ORDER BY Population DESC LIMIT 1000'
con.text_factory = str
cur.execute(query)
resultset = cur.fetchall()
# extract column names
col_names = [cn[0] for cn in cur.description]
print("%10s %30s %10s" % tuple(col_names))
print("="*(10+1+30+1+10))
for row in resultset:
print("%10s %30s %10s" % row)
except sqlite3.Error as err:
print("[ERROR]:", err)
执行上述代码:
python a.py world.sql world.db
python b.py world.db