- Relating variables with scatter plots
- Emphasizing continuity with line plots
- Showing multiple relationships with facets
距离上次写博客已经过去10天了,对于这件事我需要很认真的反省一下,这些天我一直在背六级英语单词以及写课程作业,对于课外的专业知识的学习耽搁了很久,以至于时隔这么久我现在坐在电脑前不知道写一些什么东西。对于今天出现的情况我很严肃的对自己说,这样的情况我不希望看到第二次。
这一篇博客就是对Seaborn库官方教程的学习及代码重现,没有太多的技术含量,只是对于现有教程的一个翻译与总结。
首先介绍一下有关于seaborn库中自带的数据集,可以利用如下函数进行下载:
import seaborn as sns
sns.load_dataset("name")
其中,name为你需要用到的数据的名称,第一次会将数据集下载到本地,后续使用时就可以不用再重新下载。如果你使用的是anaconda应该是在C盘User的目录下(没有试过),笔者使用的是Win Python,下载之后的目录是在./settings/seaborn-data/...的目录下。也可以从官网上下载之后使用pandas中的read_csv()函数及逆行加载,其效果是一样的。
导入需要用的包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid')
Relating variables with scatter plots
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip", data=tips)
结果如下图所示:
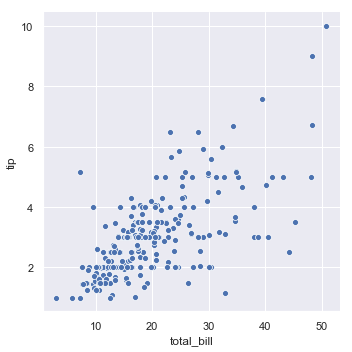
散点图在统计可视化中用的比较多,它能够用一系列的点很好的展示两个变量之间的关系(两个变量必须是数值型的),绘制散点图可以使用函数scatterplot()来绘制,上例中使用的是函数replot()函数,该函数的默认图形类型就是散点图,效果和scatterplot()是一样的。
除了上述普通的散点图,还可以在函数中添加参数hue,该参数的值对应着一个分类变量,示例如下图所示:
sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips)
结果如下图所示:
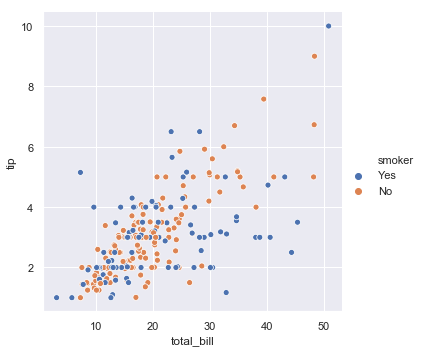
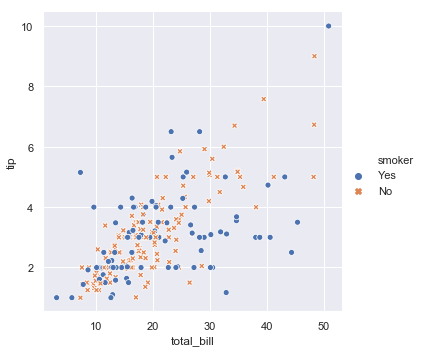
在上图的基础上再增加一个“style”参数,可以用另一种点的记号来展示类别变量,实力如下图所示:
sns.relplot(x="total_bill", y="tip", hue="smoker", style="smoker", data=tips)
结果如下图所示:
还可以在一个散点图上展示四个变量:
sns.relplot(x="total_bill", y="tip", hue="smoker", style="time", data=tips)
结果如下图所示:
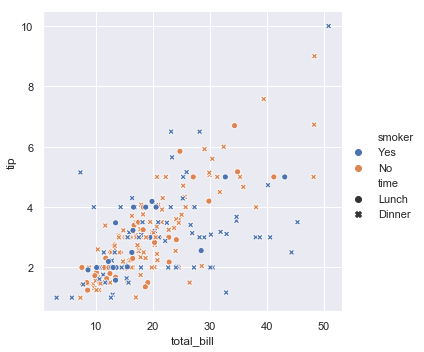
上面的例子中参数“hue”对应的值是一个分类变量,如果是数值型变量就会是如下例:
sns.relplot(x="total_bill", y="tip", hue="size", data=tips)
结果如下图所示:
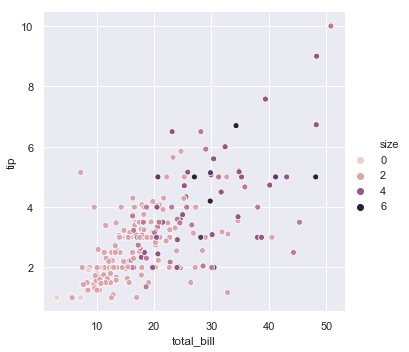
还可以自定义调色板,这里使用字符串接口定制了一个sequential palette到cubehelix_palette()。
sns.relplot(x="total_bill", y="tip", hue="size", palette="ch:r=-.5,l=.75", data=tips)
结果如下图所示:

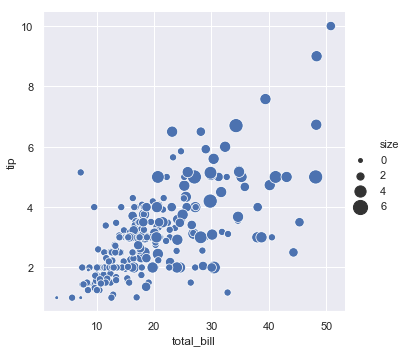
还可以通过点的大小来展示一维变量:
sns.relplot(x="total_bill", y="tip", size="size", sizes=(15, 200), data=tips)
结果如下图所示:
Emphasizing continuity with line plots
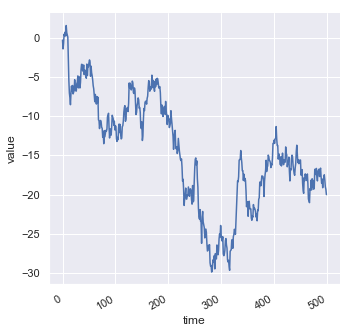
有时更希望观察某一变量随时间的变化规律,这时候可以利用线图来绘制图表。对于这一类的图表,可以使用函数lineplot()来绘制,同时还可以使用函数replot(..., kine="line")来绘制。
df = pd.DataFrame(dict(time=np.arange(500), value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
结果如下图所示:
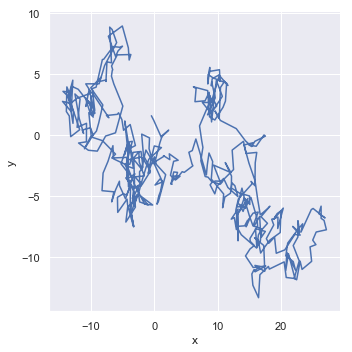
函数lineplot()默认将y绘制为x的函数,因此会对x进行排序。参数“sort”可以不对x进行排序:
df = pd.DataFrame(np.random.randn(500, 2).cumsum(axis=0), columns=["x", "y"])
sns.relplot(x="x", y="y", sort=False, kind="line", data=df)
结果如下图所示:
Aggregation and representing uncertainly
在实际中,大多数收集到的数据中x对应的y值不止一个,seaborn默认是通过在平均值周围绘制平均值以及95%置信区间聚合每个x值得多个测量值:
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint", y="signal", kind="line", data=fmri)
结果如下图所示:
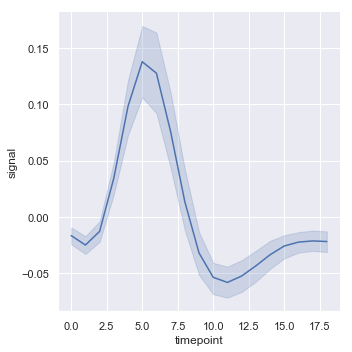
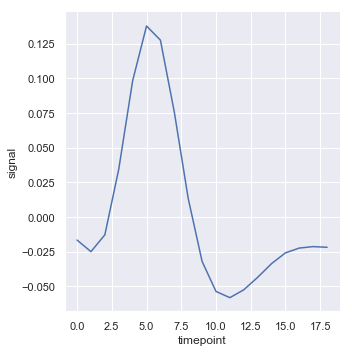
置信区间是使用booststrapping计算的,对于更大量的时间密集型数据它可能没有办法计算:
sns.relplot(x="timepoint", y="signal", ci=None, kind="line", data=fmri)
结果如下图所示:
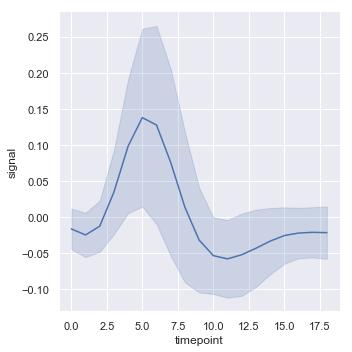
对于较大的数据有另一个选择,可以绘制标准差代替置信区间来表示分布在每个时间点的分布。
sns.relplot(x="timepoint", y="signal", kind="line", ci="sd", data=fmri)
结果如下图所示:
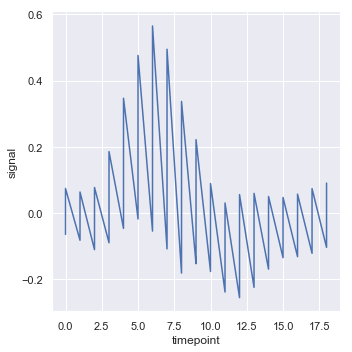
若要完全去掉聚合效果,可将参数“estimator”设置为None,注意:若每个点有多个观测值就会出现奇怪的结果:
sns.relplot(x="timepoint", y="signal", estimator=None, kind="line", data=fmri)
结果如下图所示:
Plotting subsets of data with semantic mappings
函数lineplot()与scatterplot()有同样可设置的参数:hue、size、style
sns.relplot(x="timepoint", y="signal", hue="event", kind="line", data=fmri)
结果如下图所示:
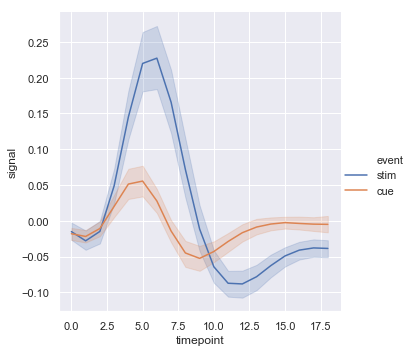
再增加一个style则会改变线的类型:
sns.relplot(x="timepoint", y="signal", hue="region", style="event", kind="line", data=fmri)
结果如下图所示:
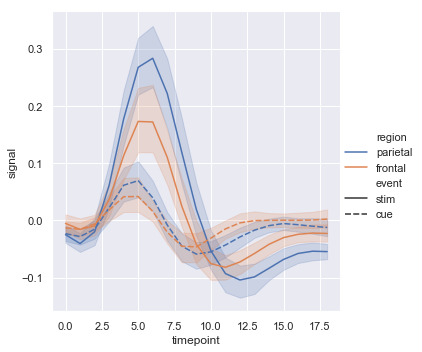
还可以改变线的类型,设置参数“dashes=False”以及“markers=True”:
sns.relplot(x="timepoint", y="signal", hue="region", style="event", dashes=False, markers=True, kind="line", data=fmri)
结果如下图所示:
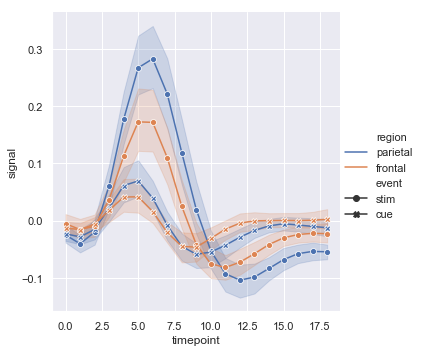
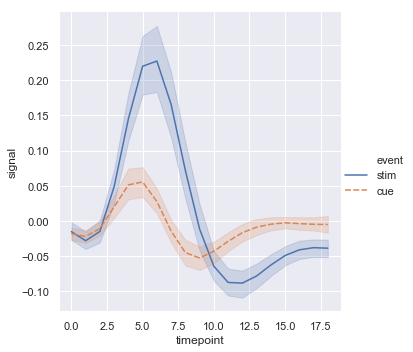
当只增加一个分类变量时,可以同时更改颜色和线型,当被打印成黑白时更易观看:
sns.relplot(x="timepoint", y="signal", hue="event", style="event", kind="line", data=fmri)
结果如下图所示:
当你想要使用重复测量数据时(即有多个采样单位),也可以单独绘制每个采样单元:
sns.relplot(x="timepoint", y="signal", hue="region",
units="subject", estimator=None,
kind="line", data=fmri.query("event == 'stim'"))
结果如下图所示:
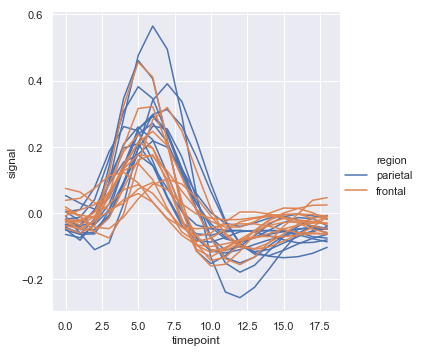
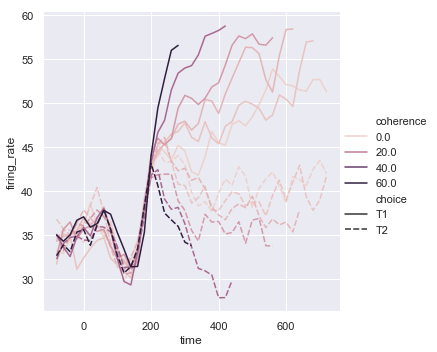
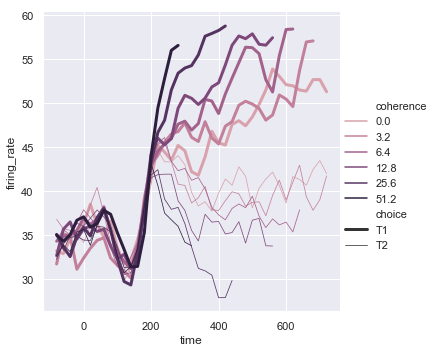
函数lineplot()中图例的默认颜色映射和处理也取决于色调:
dots = sns.load_dataset("dots").query("align == 'dots'")
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
kind="line", data=dots)
结果如下图所示:
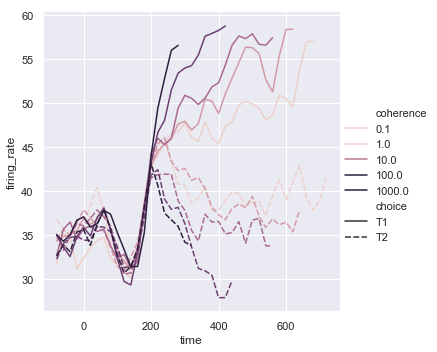
还可以将“hue”参数的值设置为数值型变量:
palette = sns.cubehelix_palette(light=.8, n_colors=6)
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
palette=palette,
kind="line", data=dots)
结果如下图所示:

还可以改变颜色的样式:
from matplotlib.colors import LogNorm
palette = sns.cubehelix_palette(light=.7, n_colors=6)
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
hue_norm=LogNorm(),
kind="line", data=dots)
结果如下图所示:
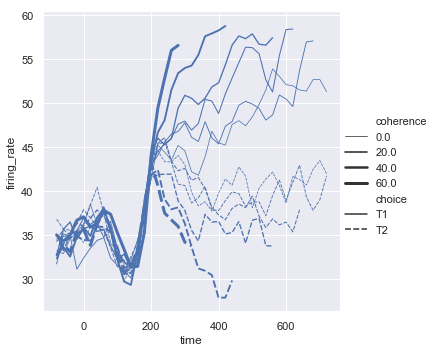
The third semantic, size, changes the width of the lines:
sns.relplot(x="time", y="firing_rate",
size="coherence", style="choice",
kind="line", data=dots)
结果如下图所示:
即使“size”变量通常为数值型变量,但也可以将分类变量与行的宽度映射。但是这样很难区分粗线还是细线,当高频可变时,很难觉察:
sns.relplot(x="time", y="firing_rate",
hue="coherence", size="choice",
palette=palette,
kind="line", data=dots)
结果如下图所示:
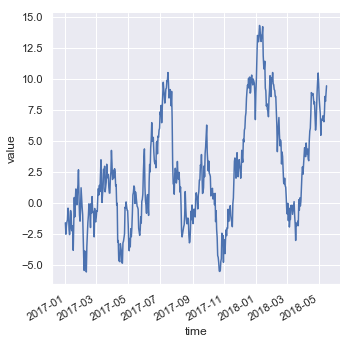
Plotting with date data
由于Seaborn的底层是matplotlib,因此可以利用matplotlib在刻度标签中设置日期格式:
df = pd.DataFrame(dict(time=pd.date_range("2017-1-1", periods=500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
结果如下图所示:
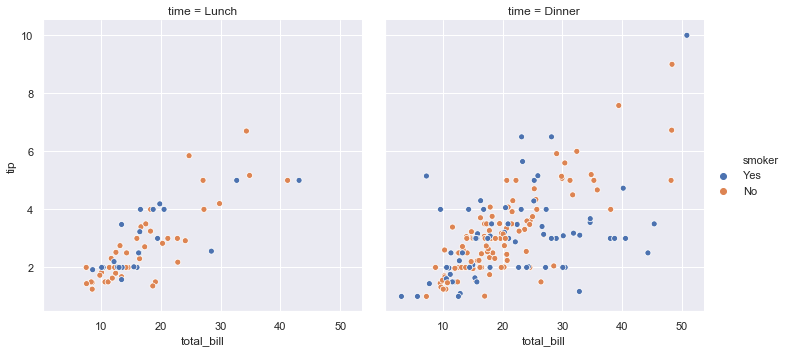
Showing multiple relationships with facets
函数replot()是基于FacetGrid的,所以可以很容易显示更多变量。这意味着可以创建多个轴并在轴上绘制数据子集:
sns.relplot(x="total_bill", y="tip", hue="smoker",
col="time", data=tips)
结果如下图所示:
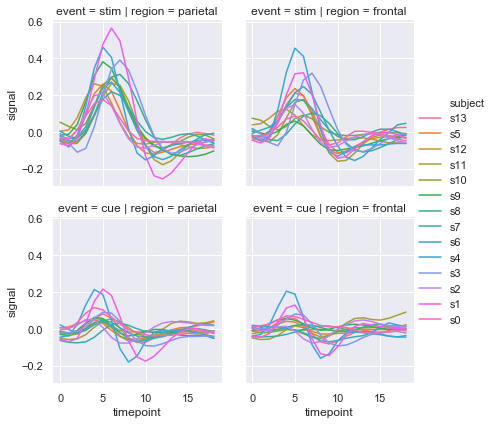
你可以这样展示两个变量的影响:一个在列上显示变量的各个类别,一个在行上显示变量的各个类别,当添加更多变量时,需要减小图形大小:
sns.relplot(x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3,
kind="line", estimator=None, data=fmri)
结果如下图所示:
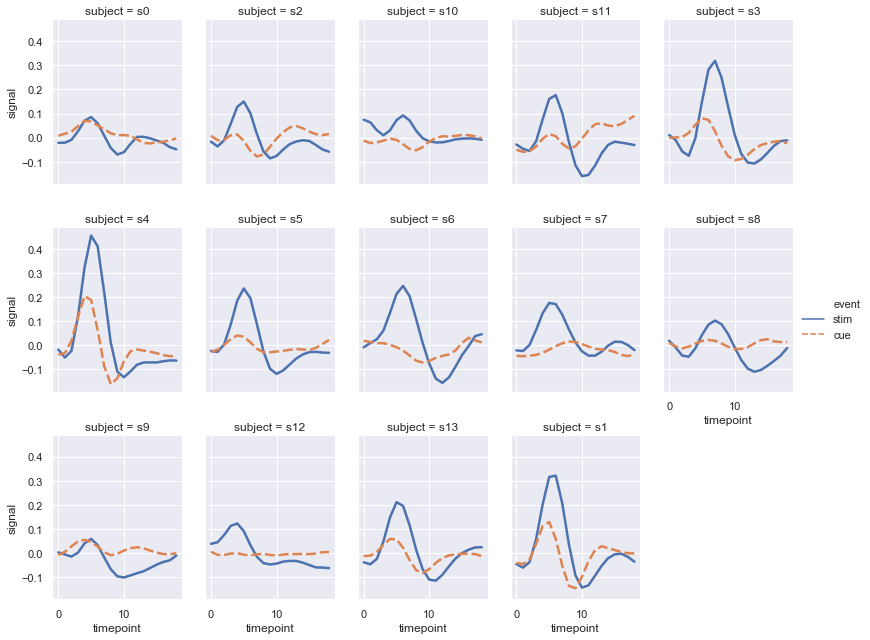
当你检查变量的多个类别的效果,最好将变量分布到列上:
sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"))
结果如下图所示:
参考文献:
http://seaborn.pydata.org/tutorial/relational.html