- Categorical scatterplots
- Distributions of observations within categories
- Statistical estimation within categories
- Plotting “wide-form” data
- Showing multiple relationships with facets
有关分类变量的绘制
当你想展示的变量中其中有一个分类变量,则可以用本篇里面的函数进行绘制图形。
Categorical scatterplots:
stripplot()(with parameter “kind=’strip’; default”)swarmplot()(with parameter “kind=’swarm’”)
Categorical distribution plots:
boxplot()(with parameter “kind=’box’”)violinplot()(with parameter “kind=’violin’”)boxenplot()(with parameter “kind=’boxen’”)
Categorical estimate plots:
pointplot()(with parameter “kind=’point’”)barplot()(with parameter “kind=’bar’”)countplot()(with parameter “kind=’count’”)
接下来,导入本节需要用的包,数据集部分参考我的上一篇博客: Seaborn——Visualizing statistical relationship
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='ticks', color_codes=True)
Categorical scatterplots
函数catplot()默认的图表类型是散点图。散点图一般有两种类型:stripplot()(条状散点图)以及swarmplot()(蜂群散点图)
tips = sns.load_dataset("tips")
sns.catplot(x="day", y="total_bill", data=tips)
结果如下图所示:
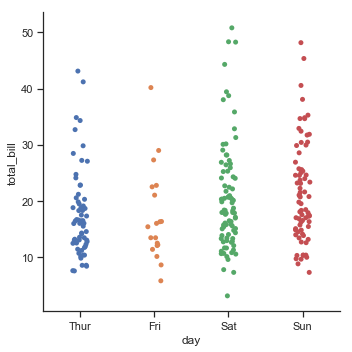
其中,参数“jitter”控制jitter的程度或者完全禁用:
sns.catplot(x="day", y="total_bill", jitter=False, data=tips)
结果如下图所示:
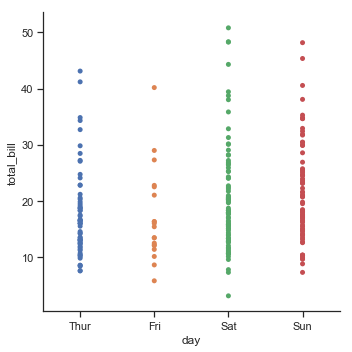
第二种方法是防止它们重叠的算法来调整沿分类轴的点。它能更好的表示观测值的分布,但它只适合较小的数据集。这个类型的函数在函数catplot()中通过参数“kind=swarm”来激活:
sns.catplot(x="day", y="total_bill", kind="swarm", data=tips)
结果如下图所示:
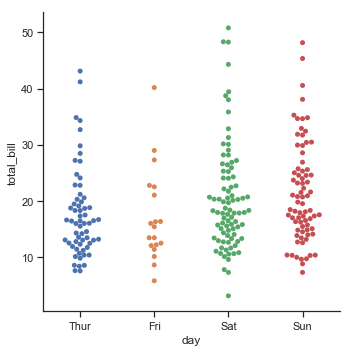
和上篇博客中一样,可以增加参数“hue”再增加一个变量进行观察:
sns.catplot(x="day", y="total_bill", hue="sex", kind="swarm", data=tips)
结果如下图所示:
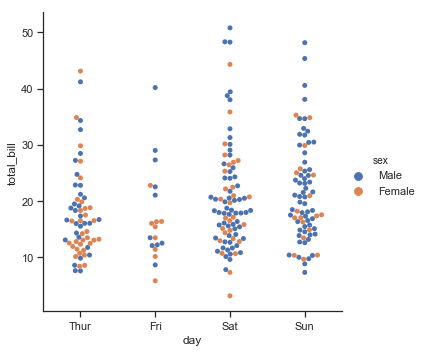
Seaborn中对于分类变量会尽量推断类别的顺序,来进行排序:
sns.catplot(x="size", y="total_bill", kind="swarm", data=tips.query("size != 3"))
结果如下图所示:
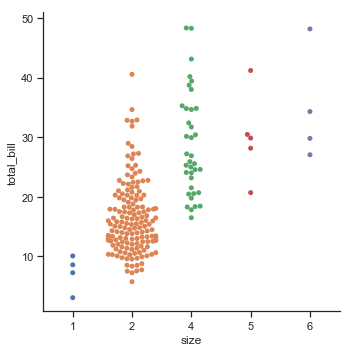
除了默认顺序还可以使用order参数在特定于绘图的基础上控制排序。在同一个图中绘制多个分类图这个参数将非常重要:
sns.catplot(x="smoker", y="tip", order=["No", "Yes"], data=tips)
结果如下图所示:
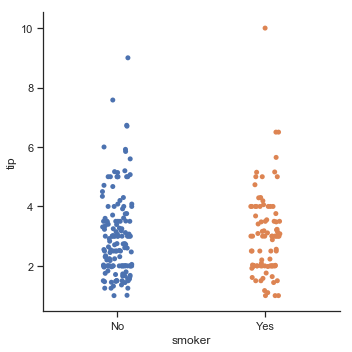
当分类变量的名称较长或者类别较多时,可以将散点图的横纵坐标转置一下:
sns.catplot(x="total_bill", y="day", hue="time", kind="swarm", data=tips)
结果如下图所示:
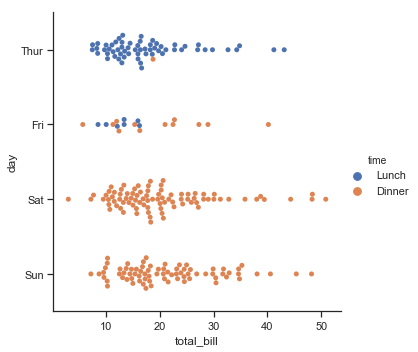
Distributions of observations within categories
当数据集大小增加时,分类散点图可以提供的信息变得有限,下面提供集中方法可以方便地在类别层次上进行比较。
Boxplots
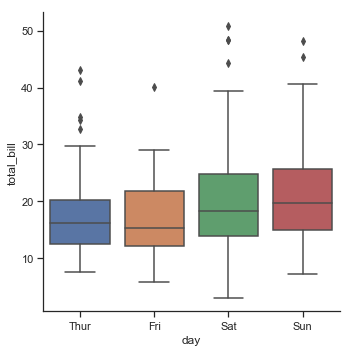
首先是箱线图(Boxplot),其中显示了三个四分位值和极值,以及离群值。
sns.catplot(x="day", y="total_bill", kind="box", data=tips)
结果如下图所示:
在上述基础上同样可以增加参数“hue”,
sns.catplot(x="day", y="total_bill", hue="smoker", kind="box", data=tips)
结果如下图所示:
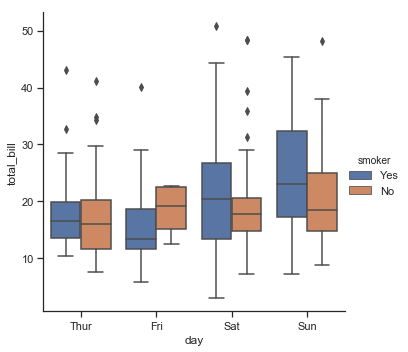
当hue参数值的分类变量与x轴的分类变量有关时,这时会出现一部分箱线图在左,一部分箱线图在右:
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.catplot(x="day", y="total_bill", hue="weekend", kind="box", data=tips)
结果如下图所示:
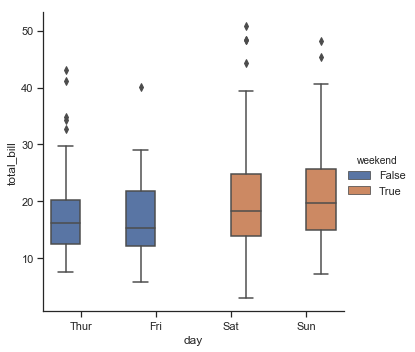
我们发现这个图很丑,所以可以通过将参数“dodge”设置为False就可避免这种情况。
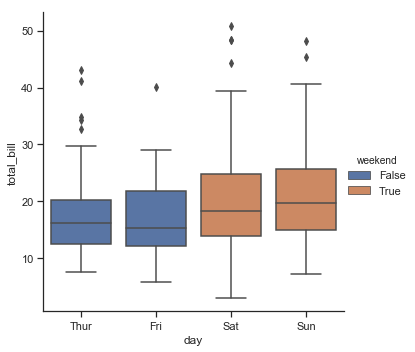
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.catplot(x="day", y="total_bill", hue="weekend",
kind="box", dodge=False, data=tips)
结果如下图所示:
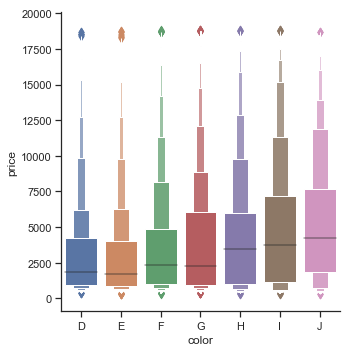
另一个很类似于箱线图的图boxenplot(),这个相比于箱线图能够显示更多的信息,我们可以通过这个图看到数据集的分布,因此这个图适合更大的数据集。
diamonds = sns.load_dataset("diamonds")
sns.catplot(x="color", y="price", kind="boxen",
data=diamonds.sort_values("color"))
结果如下图所示:
Violinplots
另一种方法就是violinplot(),它时结合了boxplot和kernel density estimation两种图,因此它能够展示更多的信息:
sns.catplot(x="total_bill", y="day", hue="time",
kind="violin", data=tips)
结果如下图所示:
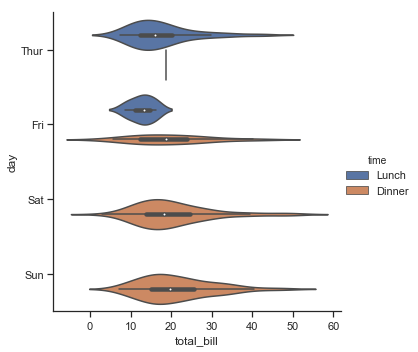
这种方法使用KDE来提供更丰富的值分布描述,缺点是需要调整其他参数:
sns.catplot(x="total_bill", y="day", hue="time",
kind="violin", bw=.15, cut=0, data=tips)
结果如下图所示:
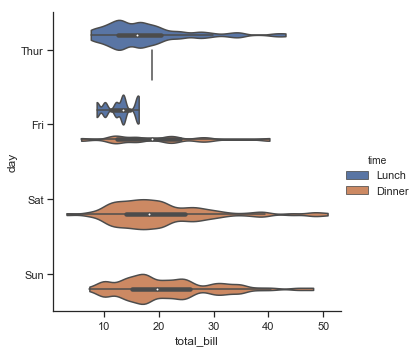
由于violinplot中左右对称,所以在进行对比时,为了表示的更加明显,可以将两个对比的图各取一半放在一起,这样可以更加节省位置,并且能够更加明显的对比两个数据:
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", split=True, data=tips)
结果如下图所示:
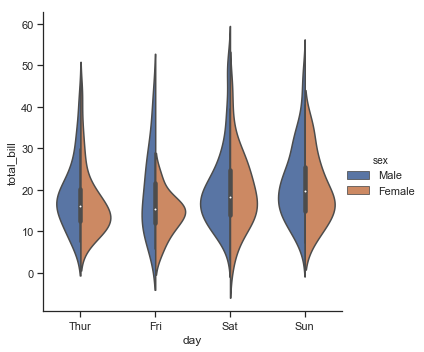
最后,violinplot还有一个选项,显示每个单独观察结果的方法,这种适合小量的数据集,数据集过大就失去了它的意义:
sns.catplot(x="day", y="total_bill", hue="sex",
kind="violin", inner="stick", split=True,
palette="pastel", data=tips)
结果如下图所示:
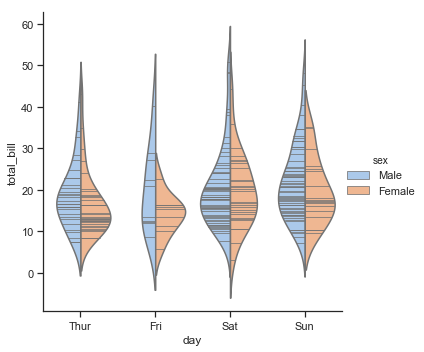
它还能够结合swarmplot()(蜂群图)或stripplot():
g = sns.catplot(x="day", y="total_bill", kind="violin", inner=None, data=tips)
sns.swarmplot(x="day", y="total_bill", color="k", size=3, data=tips, ax=g.ax)
结果如下图所示:
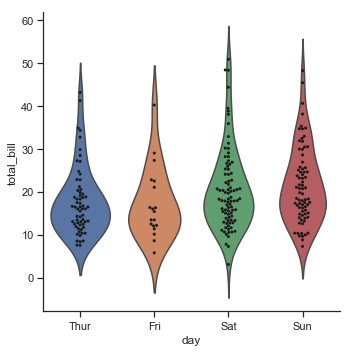
g = sns.catplot(x="day", y="total_bill", kind="violin", inner=None, data=tips)
sns.stripplot(x="day", y="total_bill", color="k", size=3, data=tips, ax=g.ax)
结果如下图所示:
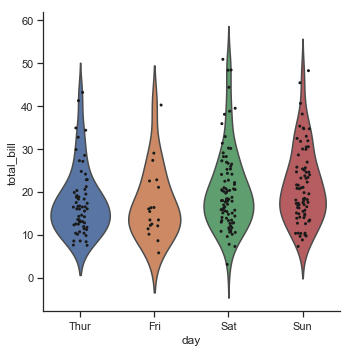
Statistical estimation within categories
当不想显示每个类别中的分布而是想要知道中心趋势的估计值,可以用下面的方法。
Bar plots
其中一个方法就是Barplot,barplot()函数对完整的数据集进行操作,并应用一个函数来获取估计值(默认取平均值)。当每个类别中有多个观测值时,它还使用bootstrapping计算估计值周围的置信区间,并使用误差条绘制:
titanic = sns.load_dataset("titanic")
sns.catplot(x="sex", y="survived", hue="class", kind="bar", data=titanic)
结果如下图所示:
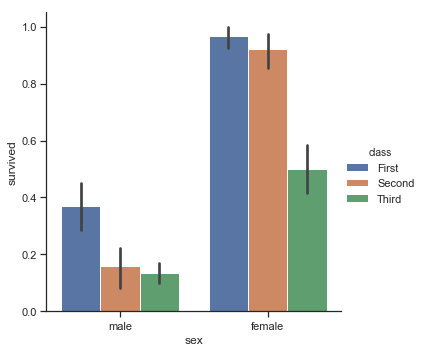
当你只想显示每个类别的观测数量,而非统计值时,可以使用函数countplot()。(这类似于分类变量而不是数值变量上的直方图)
sns.catplot(x="deck", kind="count", palette="ch:.25", data=titanic);
结果如下图所示:
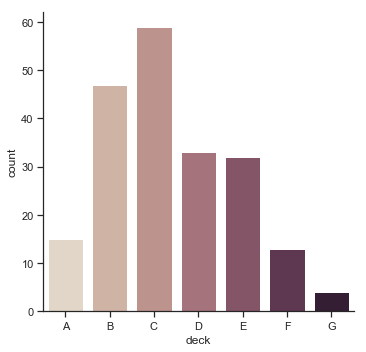
可以通过之前讲过的函数调用barplot()以及countplot():
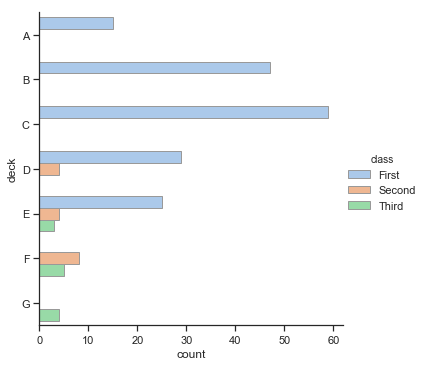
sns.catplot(y="deck", hue="class", kind="count",
palette="pastel", edgecolor=".6", data=titanic)
结果如下图所示:
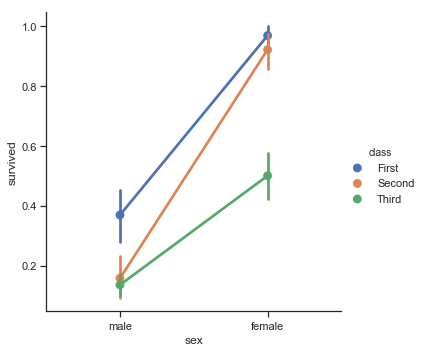
Point plots
函数pointplot()提供了另一种可视化相同信息的样式。该函数还用另一个轴上的高度来显示估计值,而不是显示一个完整的条,它绘制了点估计和置信区间。另外,pointplot()连接来自同一色调类别的点。这使得我们很容易看出主关系是如何随着色调语义的变化而变化的。
sns.catplot(x="sex", y="survived", hue="class", kind="point", data=titanic)
结果如下图所示:
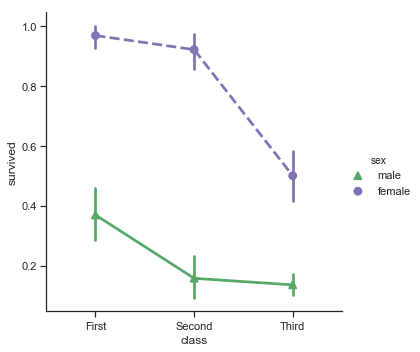
更改样式:
sns.catplot(x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic)
结果如下图所示:
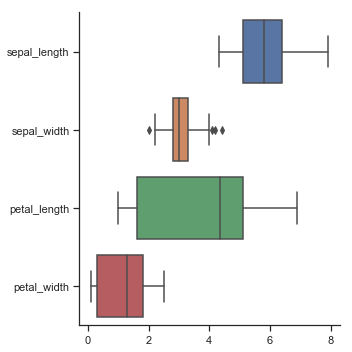
Plotting “wide-form” data
我们可以将boxplot整个图横置过来(当你的数据更适合横向放置时),通过参数orient来进行设置:
iris = sns.load_dataset("iris")
sns.catplot(data=iris, orient="h", kind="box")
结果如下图所示:
axes-level函数更适合pandas或者numpy格式的数据,而不是DataFrame:
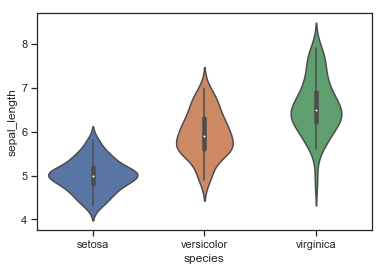
sns.violinplot(x=iris.species, y=iris.sepal_length)
结果如下图所示:
控制上述函数绘制图形的大小和形状需要通过matplotlib命令自行设置:
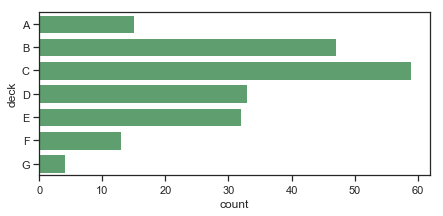
f, ax = plt.subplots(figsize=(7, 3))
sns.countplot(y="deck", data=titanic, color="g")
结果如下图所示:
Showing multiple relationships with facets
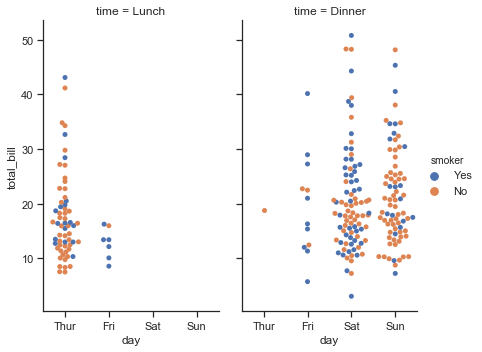
与replot()一样,catplot()是在facetgrid上构建的,因此很容易添加faceting变量来绘制更高维度的关系:
sns.catplot(x="day", y="total_bill", hue="smoker",
col="time", aspect=.6,
kind="swarm", data=tips)
结果如下图所示:
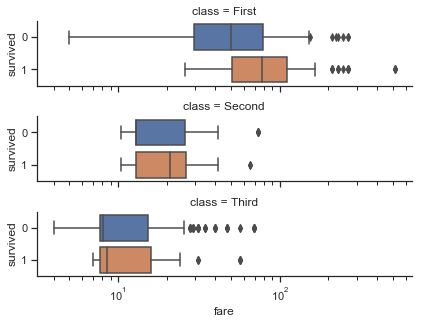
g = sns.catplot(x="fare", y="survived", row="class",
kind="box", orient="h", height=1.5, aspect=4,
data=titanic.query("fare > 0"))
g.set(xscale="log")
结果如下图所示:
参考文献:
http://seaborn.pydata.org/tutorial/categorical.html