- Abstract
- Introduction
- Selected Frameworks
- Benchmarking Methodology
- Results
- Conclusion and Recommendations
本文记录了笔者阅读的一篇论文Benchmarking Automatic Machine Learning Frameworks,一篇有关于机器学习中AutoML框架的对比分析论文。
论文原文:Benchmarking Automatic Machine Learning Frameworks。
应前几天立下的Flag,我这几天到处搜罗专业相关的学习资料,然后就找到了本篇论文,看名字挺吸引我的,但是看完这篇论文之后感觉值得我学习的部分应该在代码部分,因此我就当学英语看完了这篇论文。说实话这篇论文的文字部分写的很像一篇实验报告,但是实验的工作量应该很大。
看来我挑选论文的功夫还有待提升。虽然这篇论文文字部分价值不大,但是至少我也是花了一下午加一晚上读完了一遍(我读英语很慢),因此还是记录一下。
Abstract
AutoML servers 是设计机器学习系统以及数据科学之间的桥梁,现在对用在开源数据集的开源AutoML做一个基准化分析。文章中选择了auto-sklearn, TPOT, auto_ml, H2Os AutoML 等四种框架,分别用于一系列分类任务的数据集以及回归任务数据集进行两两对比分析。最终发现auto-sklearn在分类数据集上有更好的性能;TPOT在回归数据集上有更好的性能。
Introduction
为了AutoML更易使用的需求,创建了开源框架,以便尽可能快速、轻松的从数据中提取价值。这些平台自动化了与构建和实现通常有专门团队设计的机器学习相关的大多数任务。AutoML使得能够专注于更复杂的过程,如模型构建,而不必花费时间在耗时的过程上,如特征工程和超参数优化。
自动机器学习有多个重点领域。有一组不同的AutoML框架声称用最少的工作量就能产生最有价值的结果。这些框架将相对标准化的技术应用于多年来开发的数据,这些数据收集在开放源代码机器学习库(如Scikit Learn)中。然而,用于自动化这些技术的应用和评估的方法有很大的不同。这些方法不能仅仅根据其理论的严密性或组成算法的个别性能来评估。因此,它们必须作为一个整体通过各种数据进行实验评估。我们对AutoML最成熟的开源解决方案进行了定量评估。
Selected Frameworks
Auto_ml
Auto_ml被用于生产系统上,可以使得企业更快的从他们的客户数据中找到额外的价值。Auto_ml自动化了机器学习的许多部分。首先,通过tf-idf(自然语言处理)、数据处理(data processing)、分类编码(categorical encoding)和数字特征缩放(numeric feature scaling)实现特征工程过程的自动化。它的日期预处理包括将时间戳转换为二进制特性(如周末或工作日)以及拆分组件(如日、月、年)。当用PCA降维时,存在超过100000列的Auto_ML也执行特征降维。为了正确的预处理,这个库需要输入每个特征的类型。此外,Auto_ml自动化了模型的构建、调整、选择和集成过程。
Auto_ml使用高度优化的库,eg:scikitlearn、xgboost、tensorflow、keras和lightgbm来实现算法。他还包含分类和回归方法的预先构建的模型基础设施,这些方法的预测时间小于1millisecond。它使用来自sklearn-deap的进化网格搜索(grid search)算法优化模型。
虽然它有些特点,但是它的可扩展性很差。它在处理多分类问题时也往往表现不佳。它不支持时间限制特性,因此每个算法必须在无限长的时间内运行到完成。这与此框架在时间限制的场景(频繁重新训练的生产系统)中不能发挥作用。文章中测试框架使用的版本是2.7.0。
Auto-sklearn
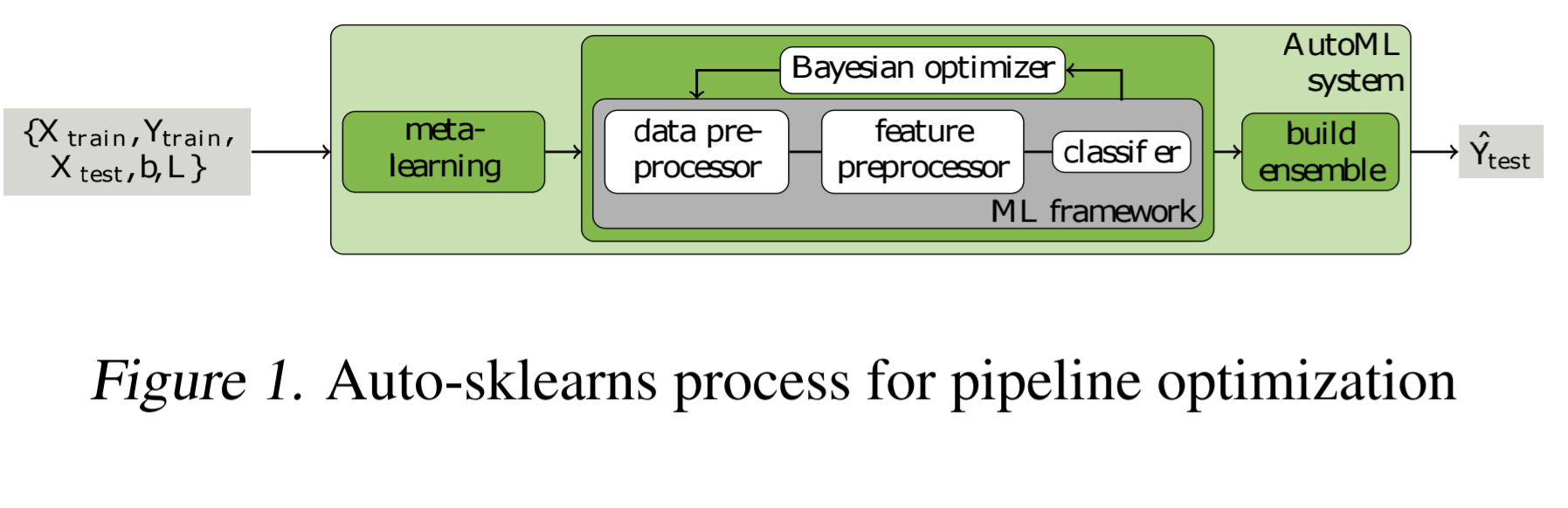
注:该图片来源于原论文。
Auto-sklearn可以自动创建一个ML pipline。它包含独热编码、数值特征标准化、PCA(主成分分析)等特征工程方法。这些模型使用sklearn估计来处理分类和回归问题。Auto-sklearn创建一个pipline并且使用贝叶斯搜索(bayesian search)来对其进行优化。默认的超参数值时使用OpenML中的140个预先训练的数据集,使用figure 1 中概述的metalearning过程热启动。它为一个数据集计算38个统计信息,并将超参数初始化为一个数据集的优化参数,该数据集的统计信息最接近训练设置。
Auto-sklearn尝试数据集上所有相关数据操纵器(manipulator)和估计器(estimators),并且可以手动进行限制。它支持多线程,该平台最大的优点是它易于集成到现有的sklearn生态系统的工具中,为扩展提供了可能。Auto-sklearn使用优化框架SMAC3实现贝叶斯搜索和速度机制以快速评估模型性能。
该包缺乏自然语言输入的能力,也缺乏自动识别输入时分类还是数值类型。并且不能处理字符串输入,需要手动来对字符串进行编码。测试该框架使用的版本是0.4.0。
TPOT
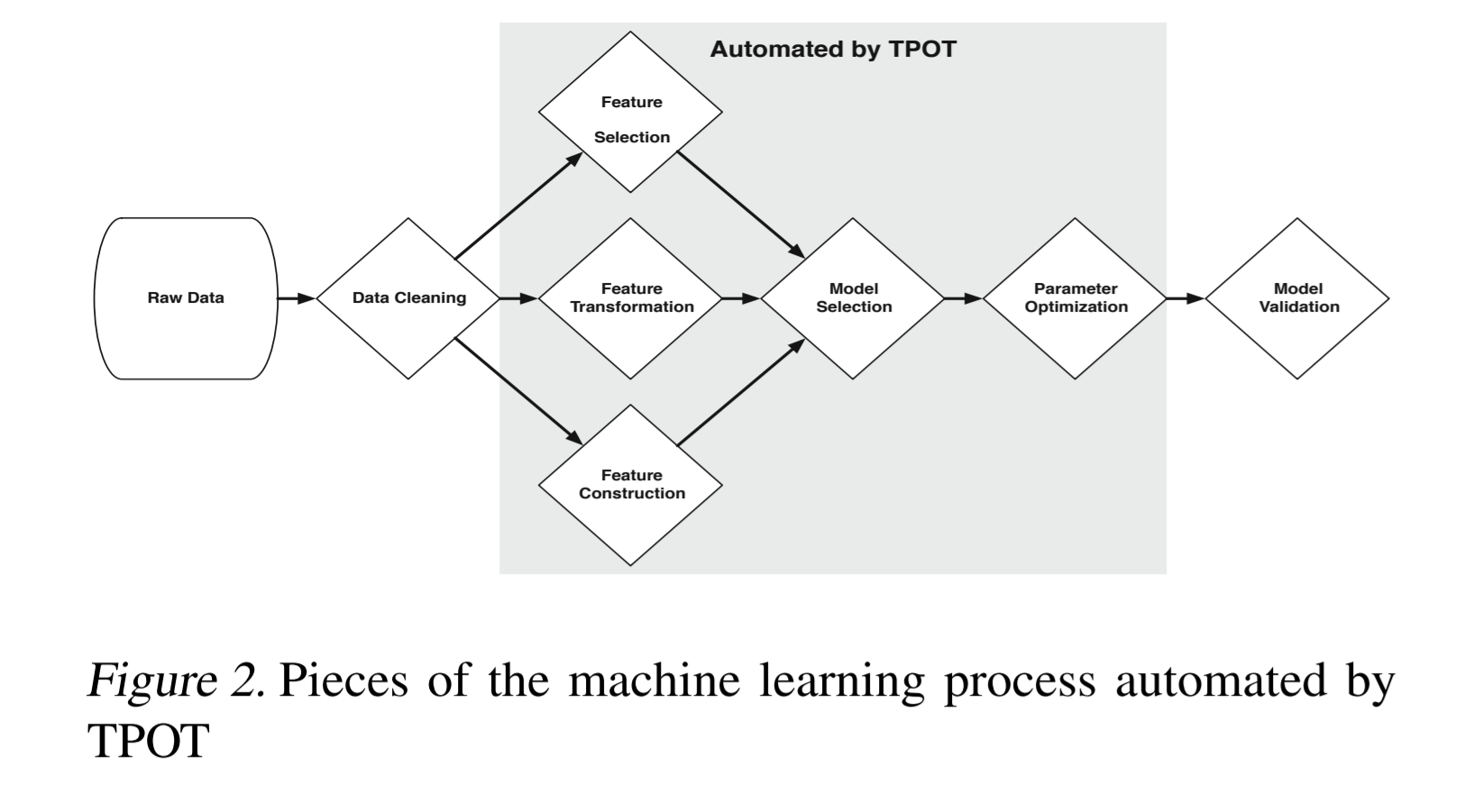
注:该图片来源于原论文。
TOPT或Tree-Based Pipeline Optimization Tool,是一个基于遗传编程(genetic programming-based)的优化器,可以生成机器学习pipeline。它使用自己的基本回归器(base regressor)和分类器方法(classifier methods)来扩展scikit learn框架。 它自动化了figure 2 中详细描述的机器学习过程的部分。
与Auto-sklearn一样,TPOT从sklearn中获取数据操纵器和估计器,其搜索空间可以通过配置文件进行限制。通过改变最大执行时间或种群(population)大小,将时间限制应用于TPOT。优化过程还支持暂停和恢复。这个框架最重要的特性是能够将模型导出到代码中,以便手工进一步修改。
TPOT不能自动处理自然语言输入,也不能处理在传入数据之前必须进行整数编码的分类字符串。还要注意,在测试这个框架时使用了0.9版。
H2O
H2O是一个类似于ScikitLearn的机器学习框架,它包含一组机器学习算法,这些算法在服务器集群上执行,可由多种接口和编程语言访问。H2O包括一个自动机器学习模块,它使用自己的算法来构建pipeline。配置仅限于算法选择、停止时间和k倍验证的程度。它对其特征工程方法和模型超参数进行穷举搜索(exhaustive),以优化其pipeline
它目前支持特征工程的插补、独热编码(one-hot encoding)和标准化(standardization),并支持广义线性模型(generalized linear models)、基本深度学习模型(base deep learning models)、梯度提升机(gradient boosting machines)和稠密随机森林(dense random forests)作为其机器学习模型。它支持两种超参数优化方法:笛卡尔网格搜索(Cartesian grid search)和随机网格搜索(random grid search)。最终的结果是一个集成模型,可以保存并重新加载到H2O框架中,用于生产系统。
H2O是用Java开发的,包括Python、JavaScript、Tableau、R和Flow(WebUI)绑定。核心代码运行在本地或远程服务器上,外部代码连接并上载要运行的作业。生产模型作为本地Java实体导出,可以加载到任何H2O集群中。
H2O的主要缺点是其大量的资源使用。在测试期间,由于垃圾收集不足,此框架在长时间运行的进程中多次失败。请注意,版本3.20.0.2用于测试此框架。
Benchmarking Methodology
Overview
为了准确比较所选择的AutoML框架,设计了一个测试平台来评估每个框架的有效性。我们使用各自的pipeline为每个选定的框架(TPOT、Auto-sklearn、h2o和auto_ml)编写代码。根据建模问题的类型、回归或分类,我们分别使用不同的度量:MSE和F1 Score(加权)。
基准测试数据集的选择是一个具有挑战性的问题。许多开放的数据集在使用前需要进行大量的预处理,并且不是以相同的形状或形式出现的。选择OpenML数据库来解决此问题。(Bischl等人,2017)OpenML在其网站上托管数据集,同时公开访问数据集的API。我们使用57个自定义分类数据集和30个自定义回归数据集对每个框架进行基准测试。
为了得到一致的结果,生成一组10个随机种子来固定随机数生成器。这将产生3480个测试项(10个种子 * 4个框架 * 87个数据集)的计算空间。我们根据对每个框架运行时的调查,将软计算时间限制为每个框架3小时,硬计算时间限制为3.5小时。计算时间和搜索空间的组合估计会导致10440个计算小时。这对于本地计算是不可行的,因此实现了一个分布式解决方案来执行基准测试套件。
Distributed Computing Setup
- AWS BATCH:
最初选择Amazon Web Services(aws)批处理框架来处理这个基准测试的并行化和负载平衡。这个框架接受来自Amazon弹性容器存储库(ECR)的Docker容器。然后在弹性容器服务(ECS)管理的弹性计算(EC2)实例集群上重复执行容器。
我们配置ECS计算集群来创建C4计算优化的EC2实例。这些实例运行在Intel Xeon E5-2666 v3处理器上,以2.6 GHz基本运行,最大为3.3 GHz。Amazons硬件虚拟机(HVM)虚拟化方法用于托管这些实例,Docker用于托管单个容器。这些实例包括每个vCPU 1.88 GB内存、每个vCPU 2到16个vCPU和250 Mbps存储带宽。ECS会自动选择实例的组合,以获得所需数量的VCPU,从而使进程完全并行化。有超过16个vcpu实例的实例可用,但是当试图在单个ec2实例上执行超过16个容器时,docker和弹性块存储(EBS)会出现一致性问题。因此,我们将ECS可用的实例类型限制在C4.4XL及以下级别。我们为每个容器分配2个vcpu和4gb内存,ECS处理其余的配置过程。
我们基于Amazon Linux映像创建Docker映像,因为它是轻量级的,并且与AWS服务兼容。此映像包含一个脚本,该脚本在运行时引导容器满足所有要求。我们还创建一个作业文件作为所有测试项的索引,并将其上载到S3。然后,我们将本地存储库推送到远程分支,并使用boto3 python框架将AWS批处理数组作业分派到计算集群。
在容器执行时,脚本克隆存储库,并提供python环境。作业文件也从S3下载并解析。AWS批处理传递给容器的唯一索引确定要执行的作业。使用作业中的OpenML数据集编号,使用OpenML API将所需的数据集下载到容器中。
最后,调用基准测试核心代码,使用作业文件中指定的数据集、框架和种子执行框架。如果框架在没有生成模型的情况下超时,我们将记录此失败,终止作业,并转到下一个测试。我们尽最大努力确保所有测试完成,并且所有测试至少有3次成功的机会。然后将结果上传到s3。这些文件被下载并在本地连接,以创建用于生成结果的最终输出文件。
- BARE METAL:
我们发现,AWS批量管理的计算环境和基于Docker的资源管理有时会导致高度并行化框架上的大型数据集出现不可预测的行为和性能。由于内存限制,大多数H2O运行失败,许多TPOT运行也失败。具体来说,如果进程使用的内存量超过批分配的数量,Docker Manager会向基准进程发送一个终止信号。这个硬限制与Amazon ECS中用于分配计算资源的内存是不可区分的,因此如果每次运行时小幅增加实例大小,就无法更改。对于内存可能激增的AutoML框架,这是一个主要问题。
另外,Java默认不遵守Docker容器CPU和内存限制,因此必须手动分配堆,这是一个已知的问题。但是,如上所述,如果垃圾收集器空间超过最大内存,则会终止JVM。这个bug是许多H2O失效的根源。
针对AWS批处理的这些限制,我们开发了一个运行在AWS上的定制分布式计算解决方案。我们使用Boto3生成EC2 spot实例,通过SSH提供它们,然后向它们分派任务列表。一旦达到进程的时间限制,调度程序就会清理实例。这也允许我们分配交换空间,这是在具有少量RAM的机器上执行H2O所必需的。只要没有达到限制,RAM的数量对这些框架的执行能力没有显著影响。使用此方法后,H2O更稳定地使用成功,并且不再因过度使用RAM而被种植。
尽管此机制不是容器化的,而AWS批处理是;相同的内存和CPU约束应用于系统,系统在相同的管理程序和硬件平台上执行,从而导致相同的操作环境。Docker的虚拟化层在RAM访问时间、RAM空间和CPU容量方面可以忽略不计。(Felter等人,2015年)
Issues Encountered
- 由于数据集之间的不一致,导致大规模执行自动机器学习框架时会出现问题;
- 数据集本身存在一些问题,例如缺失值以及本身特别大的数据集(eg:MNIST);
- 特定随机种子的失效(什么导致的失效没有看懂)。
针对于上述问题,最终解决了TPOT以及Auto_ml中的框架错误(TPOT中由于缺失值导致的错误;Auto_ml在多分类问题和多模型拟合方面的依赖性问题)。还在Auto_ml中实现了加权F1分数的度量和优化。
Individual Framework Configuration
框架的配置:
-
对于Auto-sklearn:
将任务剩余的总时间设置为总可运行时间(3 hrs),并将每次运行时间限制设置为该值的八分之一。重采样测量被设置为5折交叉验证,优化度量根据问题类型设置为加权F1分数(Weighed F1 Score)或者均方误差(MSE)。此外,在拟合估计器时,我们需要提供每个特性是否是使用OpenML源数据的分类列。 -
对于TPOT:
将generations设置为100, populations设置为100。对于分类问题,内部线性SVC估计被禁用,因为它不包含评分所需的predict proba函数。还将最大时间设置为3 hrs,将优化度量设置为加权F1分数(Weighted F1 Score)或者均方误差(MSE),并将jobs数设置为2(计算机资源的vCPUs数)。 -
对于H2O:
将线程数设置为2,最大运行时间为3.5 hrs (在0.5h内减少到1.5h,在以时间限制内实现最大化),分配给JVM的最小内存位7gigabytes(千兆字节),分配给JVM的最大内存为100gigabytes(千兆字节)(防止封顶),这时通过虚拟机配置时分配的交换分区提供。还是用了OpenML源数据手动将分类列定义为因子,并将优化度量设置为用于回归的MSE和用于分类的Weighted F1 Score。 -
对于Auto_ml:
提供了OpenML源数据,并将优化度量设置为Weighted F1 Score和MSE。还将分类估计器限制为AdaboostClassifier、ExtratreesClassifier、RandomForestClassiifier和XGBClassifier,并将回归估计器限制为Bayesianridge、ElasticNet、Lasso、Lassolars、线性相关、感知器、LogisticRegregation、Adaboostregrator、ExtratreesRegregator、无源回归器、随机森林回归器、sgdregresor和xgbregressor。无法设置Auto_ml的时间限制,因此保持再次测试的时间限制内,仅用了gridserchcv超参数优化。
Results
Dataset Analysis
数据集由57个分类问题和30个回归问题组成。需要注意的是,选择的每个数据集都不会被任何AutoML方法以任何方式在内部使用。例如,auto sklearns metalearning也使用来自OpenML的数据集进行设置。table 3 和 table 4列出了所选数据集的完整集合。
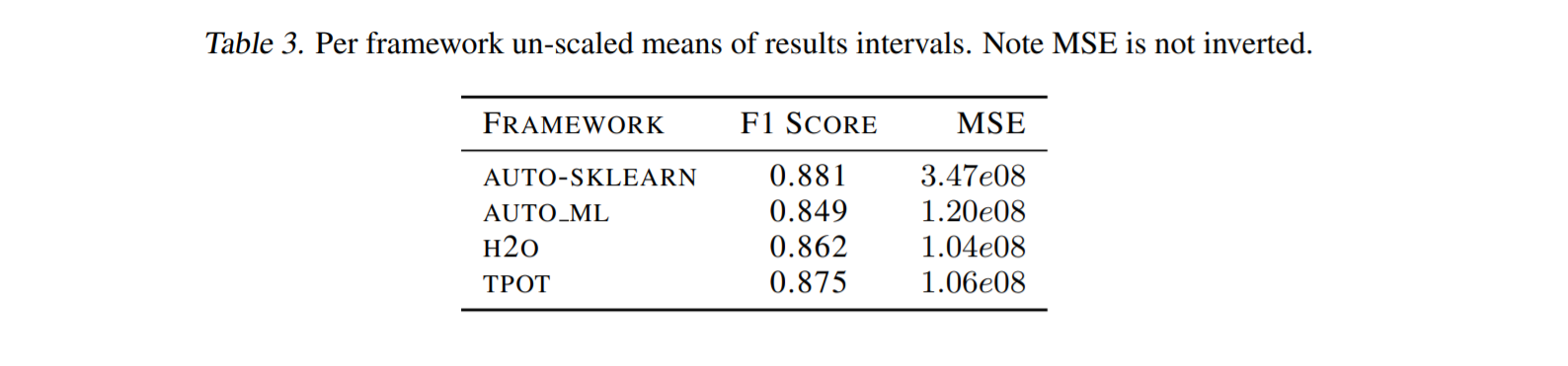
注:该图片来源于原论文。
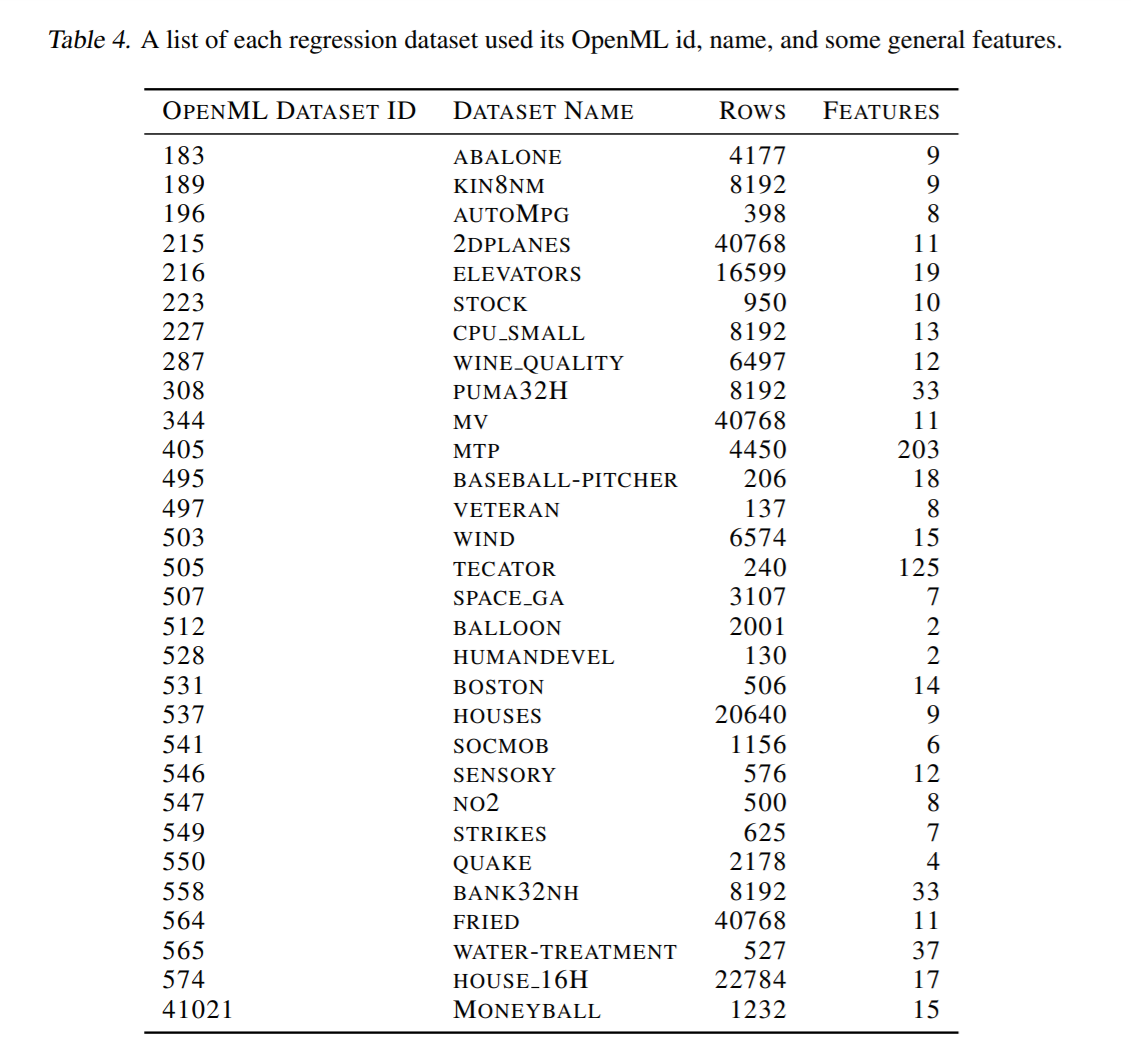
注:该图片来源于原论文。
在选择的数据集中,我们注意到数据并不完全一致,数据集之间的数据集大小、特征大小和分类类别数等因素也不同。我们在这里展示了我们的数据中存在的偏差,这些偏差可能对从这一点得出的结论没有重大影响。
figure 5 展示了数据集的一般形状,分为分类和回归任务。我们观察到,分类主要存在作为二元分类,回归。行数相对均匀,分类行数稍微偏向1000行左右的数据集,回归和分类中心的特征数都在10行左右,分类也稍微偏向100行。因此,我们认为这个数据组是许多数据科学家将遇到的一般数据科学问题的代表性样本。
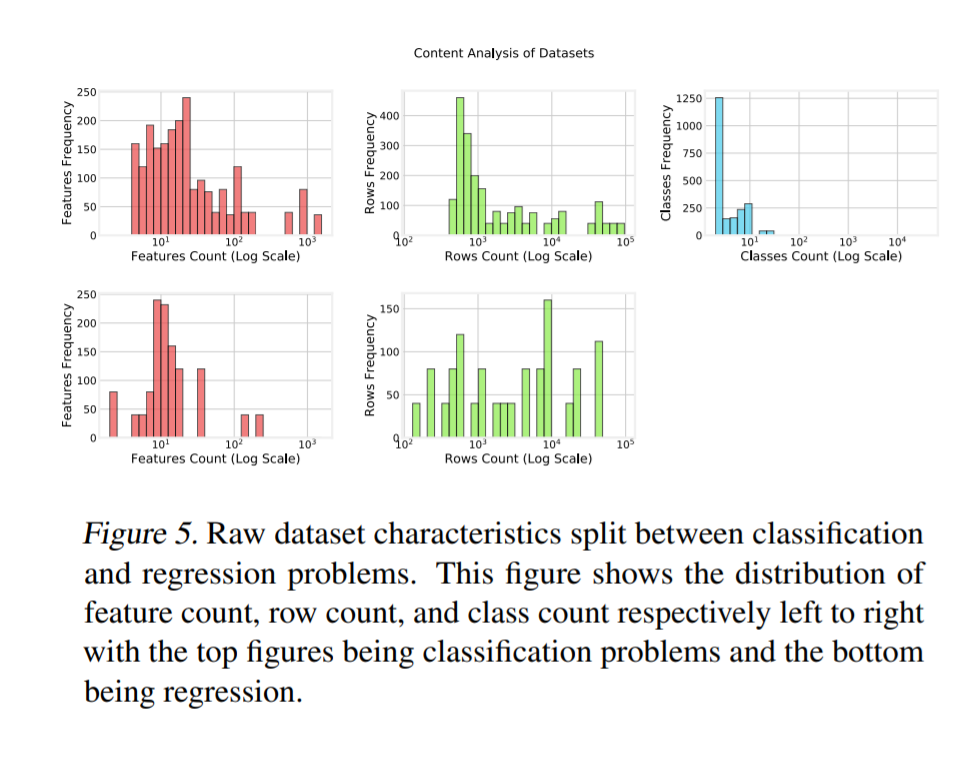
注:该图片来源于原论文。
Handling Missing Points
table 1 列出了每个框架的失败次数。共删除29个运行组合(数据集和种子)。为了保持框架的可比性,这些运行组合在所有框架中都被丢弃。这一过程共产生132个需要删除的数据点(29*4)。这相当于下降3%的百分比(116/3480次运行)。
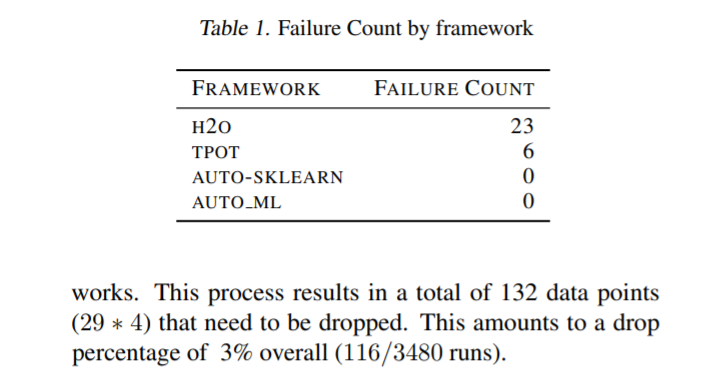
注:该图片来源于原论文。
Pairwise Framework Comparison
每个框架都使用前面提到的回归和分类数据集分割进行评估。通过框架将数据集上的加权F1分数和MSE相加来评估性能。需要注意的是,每个度量都是基于框架中的每个数据集进行标准化的,并从0扩展到1。在MSE的情况下,这些值也被反转,以便更高的值代表更好的结果,以便图形在分类和回归可视化之间保持一致。10个评估种子的平均值被用来表示框架在特定数据集上的性能。
为了可视化粒度框架的性能,指标以成对的方式绘制,如figure 3 和 figure 4 所示。着色是用来表示框架的相对性能的强度。阴影点越强表示性能差异越大。
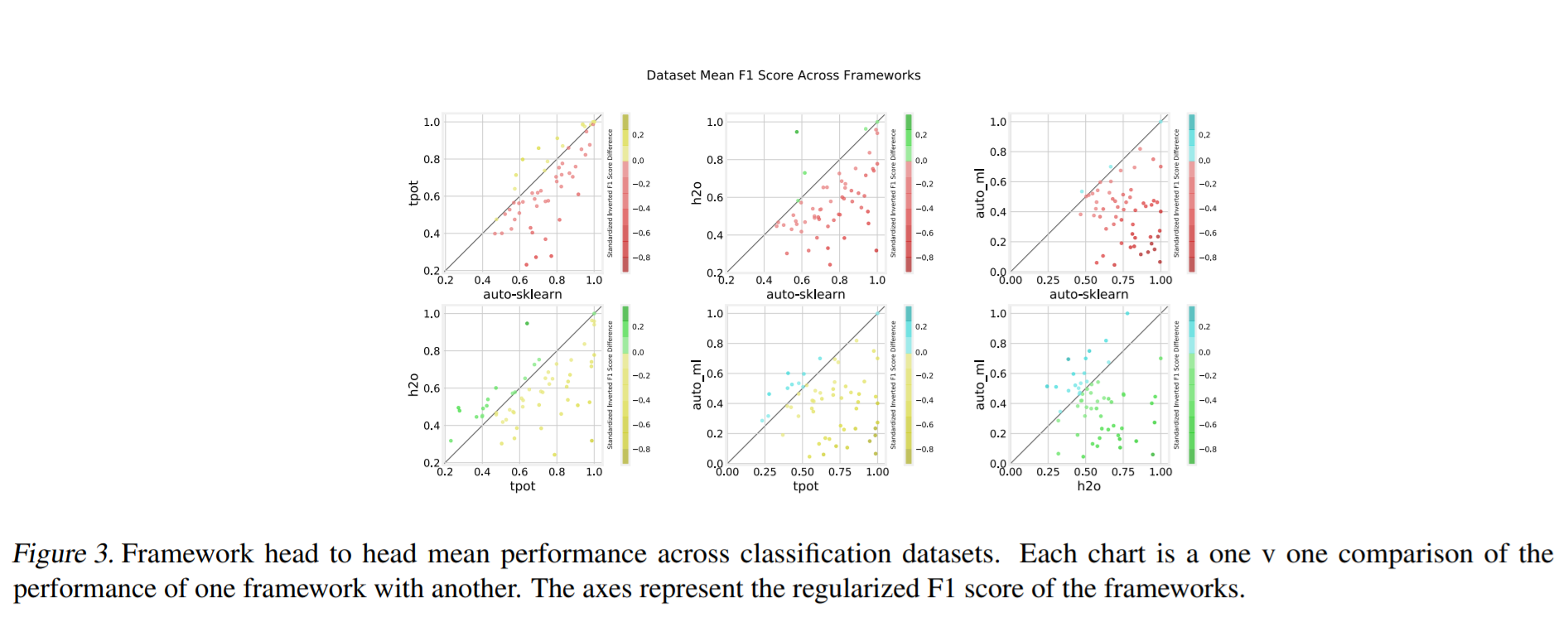
注:该图片来源于原论文。
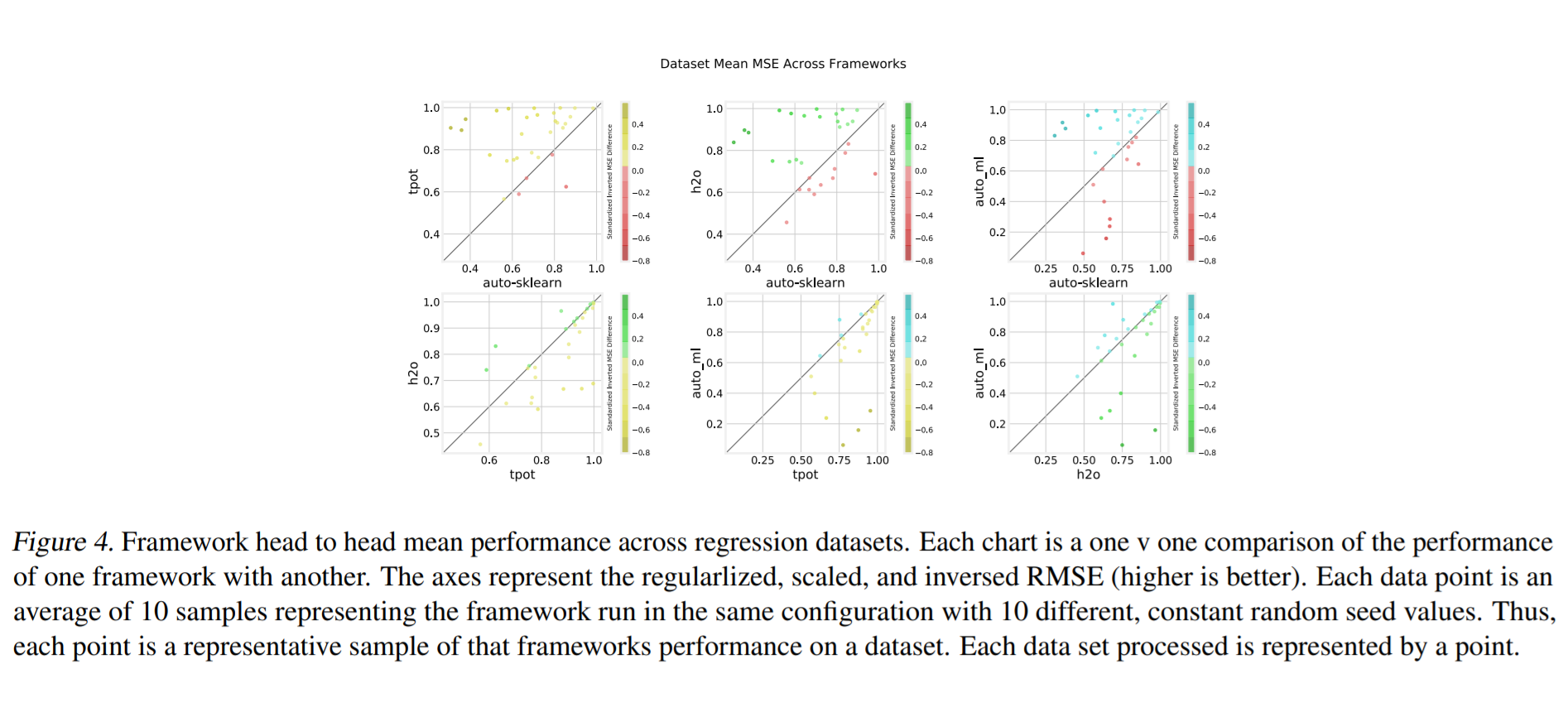
注:该图片来源于原论文。
Dataset Dependant Performance Analysis
由于我们的数据集的因素的自然聚类,重要的是要证明,没有固有的偏差存在于框架,可能有较高的性能接近这些中心。我们通过figure 6 演示了这一点,figure 6 使用滚动平均值将维度和样本大小与相应的性能指标进行了比较。横跨X轴的滚动平均线显示更清晰的趋势线并滤除噪声。注意,在这种情况下,在成对比较步骤中应用的相同变换也应用于MSE分数和加权F1分数。可以看到,在大多数情况下,框架性能在维度和样本大小的范围内是一致的。一个值得注意的异常点是Auto_mls回归测试,与其他框架相比,具有大行的数据集的性能显著下降。我们把这种退化归因于缺乏超参数优化。
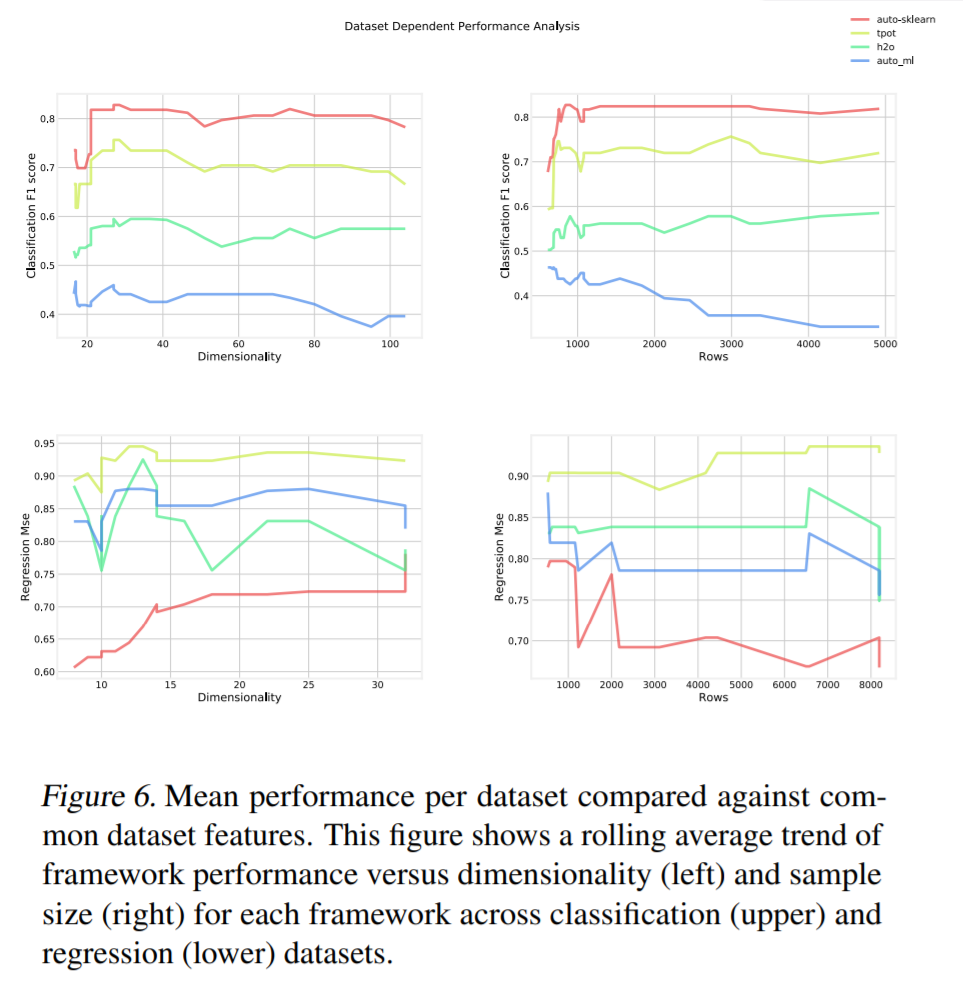
注:该图片来源于原论文。
Overall Comparison
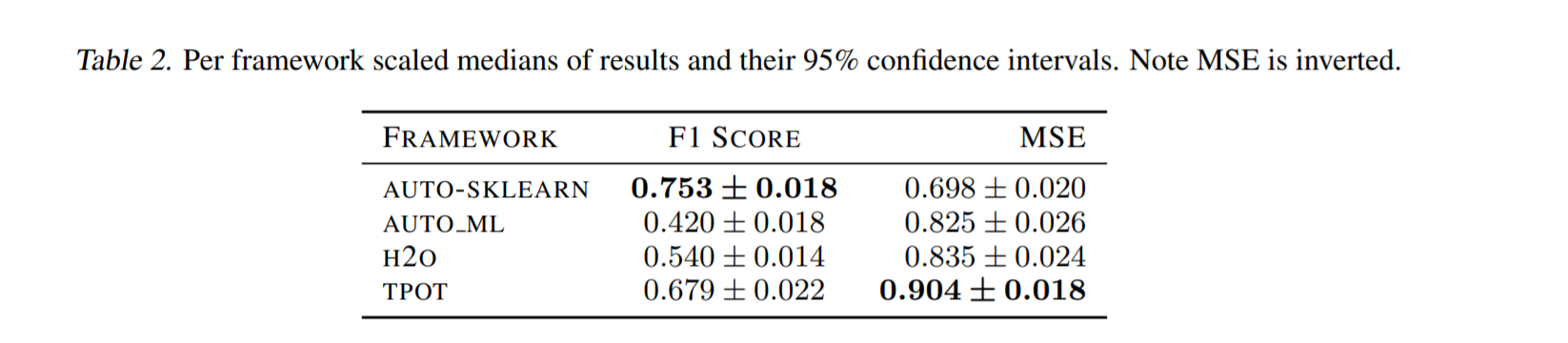
总的来说,Auto-sklearn在分类数据集上表现最好,TPOT在回归数据集上表现最好。使用了来自成对比较部分的相同统计转换。我们使用方框图简明地演示框架性能,如figure 7 和 8 所示。图中的缺口表示中位数的第95个置信区间。用于比较的未标度均值和方差见table 1 和table 2。
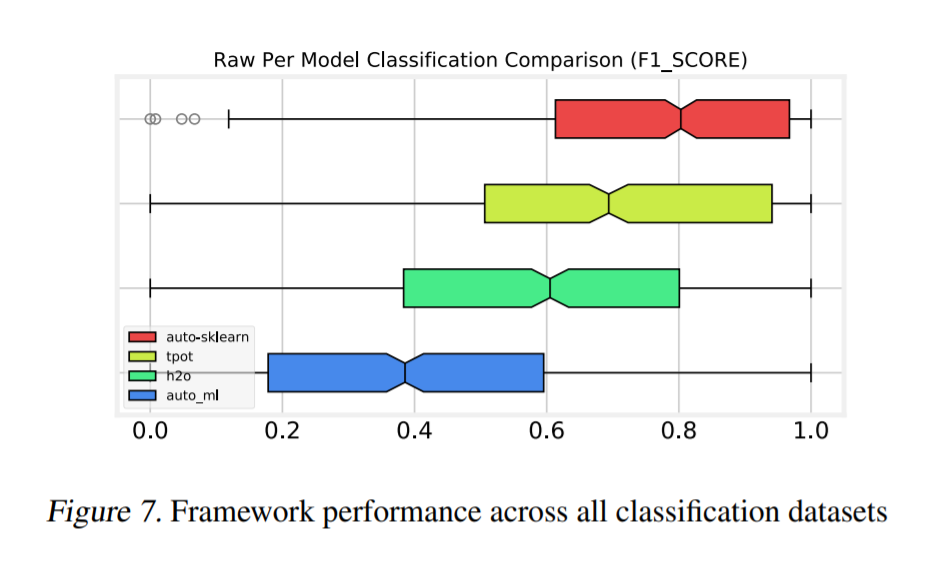
注:该图片来源于原论文。
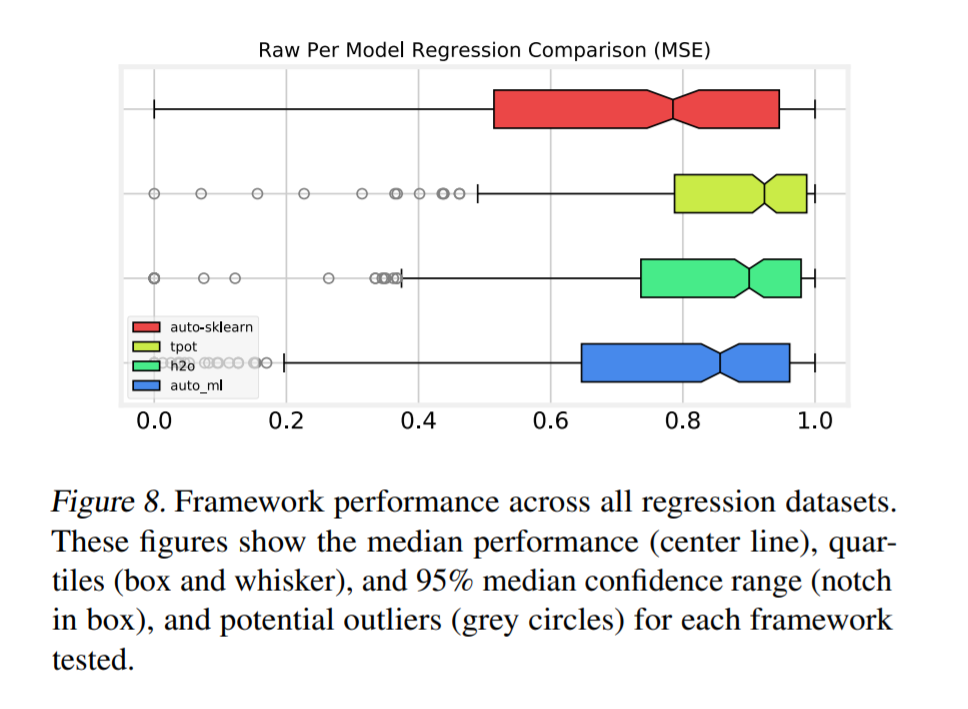
注:该图片来源于原论文。
注:该图片来源于原论文。
注:该图片来源于原论文。
Conclusion and Recommendations
我们发现Auto-sklearn在分类数据集上表现最好,TPOT在回归数据集上表现最好。这个实验的定量结果有非常高的差异,因此,仔细考虑这些独立框架的代码库、活动、特性集和目标的质量是很重要的。未来可能的工作包括对这些项目的特定特性工程、模型选择和超参数优化技术进行更细致的比较,并在开发过程中将范围扩展到更多的AutoML库和框架。

注:该图片来源于原论文。