本篇主要基于一个心脏病的数据集,根据所具有的多个特征运用逻辑回归进行预测病人是否有心脏病。
一、引言
在20世纪末我国经济大幅度增长,在人民生活水平日益提高的情况下,人们的生活方式也发生了很大的改变。不幸的是,由于生活压力的日益增长以及不规律的生活习惯极大的增加了心脏的负担,使得中国心血管疾病从1990年起持续为居民首位死亡原因。由于医疗的复杂以及医疗资源的紧缺,仅仅靠人工进行判定会使得医生的工作量加大。为了减轻医生的工作,使其更好的将精力放在更重要的地方,本文讨论是否可以通过计算机来辅助进行心脏病的预测工作,此项研究能够给人工诊断提供一定参考价值的辅助预测,并且能够帮助医生排除一些简单的预测工作,使得医生能够重点集中解决疑难杂症。
二、数据处理
2.1.数据集的特征说明:
| Colmns name | Explaination |
| Age | age in years |
| Sex | 1 = male; 0 = female |
| CP | chest pain type |
| TRESTBPS | resting blood pressure in mm Hg on admission to the hospital |
| CHOL | serum cholestoral in mg/dl |
| FPS | fasting blood sugar > 120 mg/dl 1 = true; 0 = false |
| RESTECH | resting electrocardiographic results |
| THALACH | maximum heart rate achieved |
| EXANG | exercise induced angina 1 = yes; 0 = no |
| OLDPEAK | ST depression induced by exercise relative to rest |
| SLOPE | the slope of the peak exercise ST segment |
| CA | number of major vessels 0-3 colored by flourosopy |
| THAL | 3 = normal; 6 = fixed defect; 7 = reversable defect |
| TARGET | 1 or 0 |
2.2.数据预处理
Step 1:缺失值处理
Step 2:异常值修正
Step 3:数据标准化
处理后的数据:
2.3.数据集的特征分析:
数据简单统计结果:
| age | sex | cp | … | ca | thal | target | |
|---|---|---|---|---|---|---|---|
| count | 303.000000 | 303.000000 | 303.000000 | … | 303.000000 | 303.000000 | 303.000000 |
| mean | 54.366337 | 0.683168 | 0.966997 | … | 0.729373 | 2.313531 | 0.544554 |
| std | 9.082101 | 0.466011 | 1.032052 | … | 1.022606 | 0.612277 | 0.498835 |
| min | 29.000000 | 0.000000 | 0.000000 | … | 0.000000 | 0.000000 | 0.000000 |
| 25% | 47.500000 | 0.000000 | 0.000000 | … | 0.000000 | 2.000000 | 0.000000 |
| 50% | 55.000000 | 1.000000 | 1.000000 | … | 0.000000 | 2.000000 | 1.000000 |
| 75% | 61.000000 | 1.000000 | 2.000000 | … | 1.000000 | 3.000000 | 1.000000 |
| max | 77.000000 | 1.000000 | 3.000000 | … | 4.000000 | 3.000000 | 1.000000 |
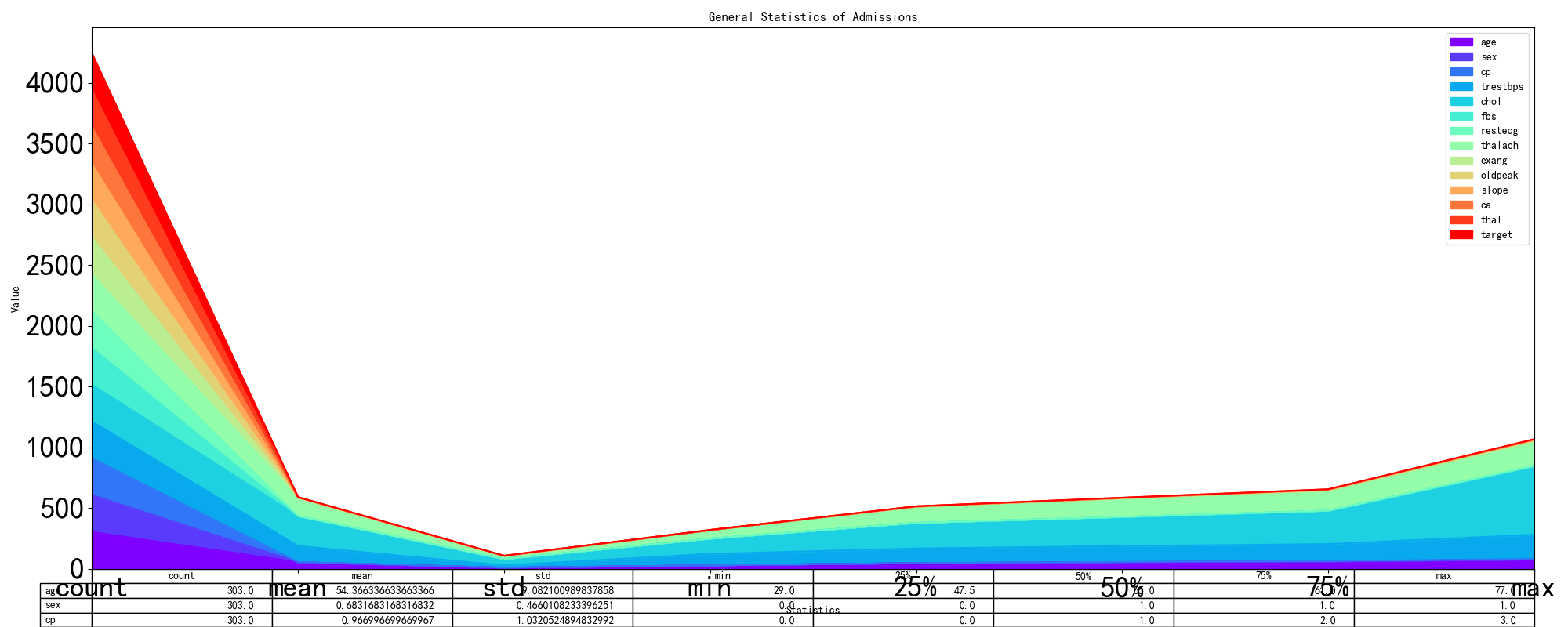
此表格中初步分析了每个维度的简单统计指标,包括计数、均值、标准差、最小值、第一四分位数、中位数、第二四分位数、最大值。可以据此初步观察每个维度的分布情况。
数据特征描述图:
 一维核密度估计图:
一维核密度估计图:
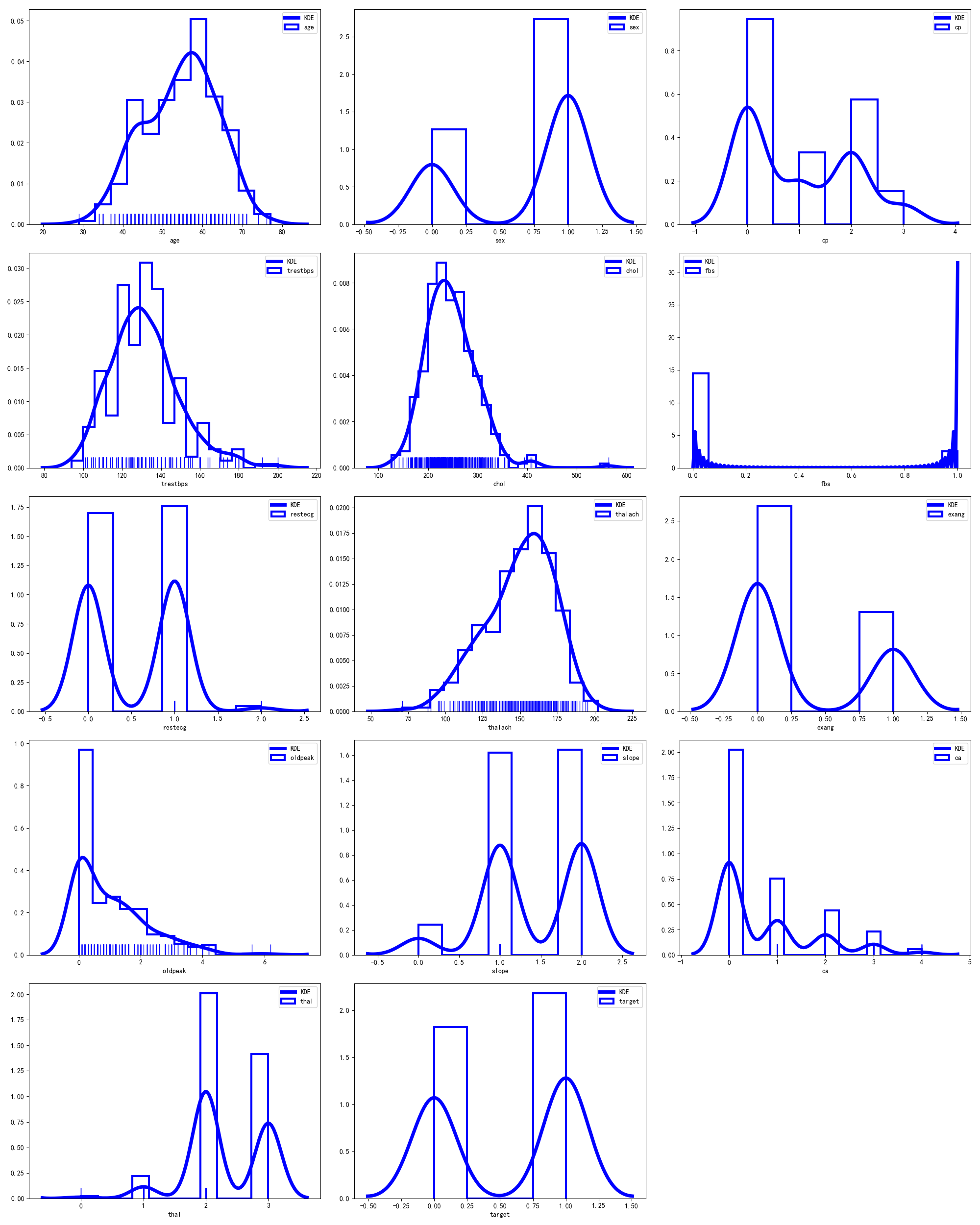
此图中画出了13个特征的核密度分布图,可以直观的看出每个维度的分布情况。例如第4幅图中可以明显的看到trestbps的的核密度估计图是呈钟形的曲线,而第8幅图中看到thalac是一个左偏的图形。
特征的相关系数热力图:
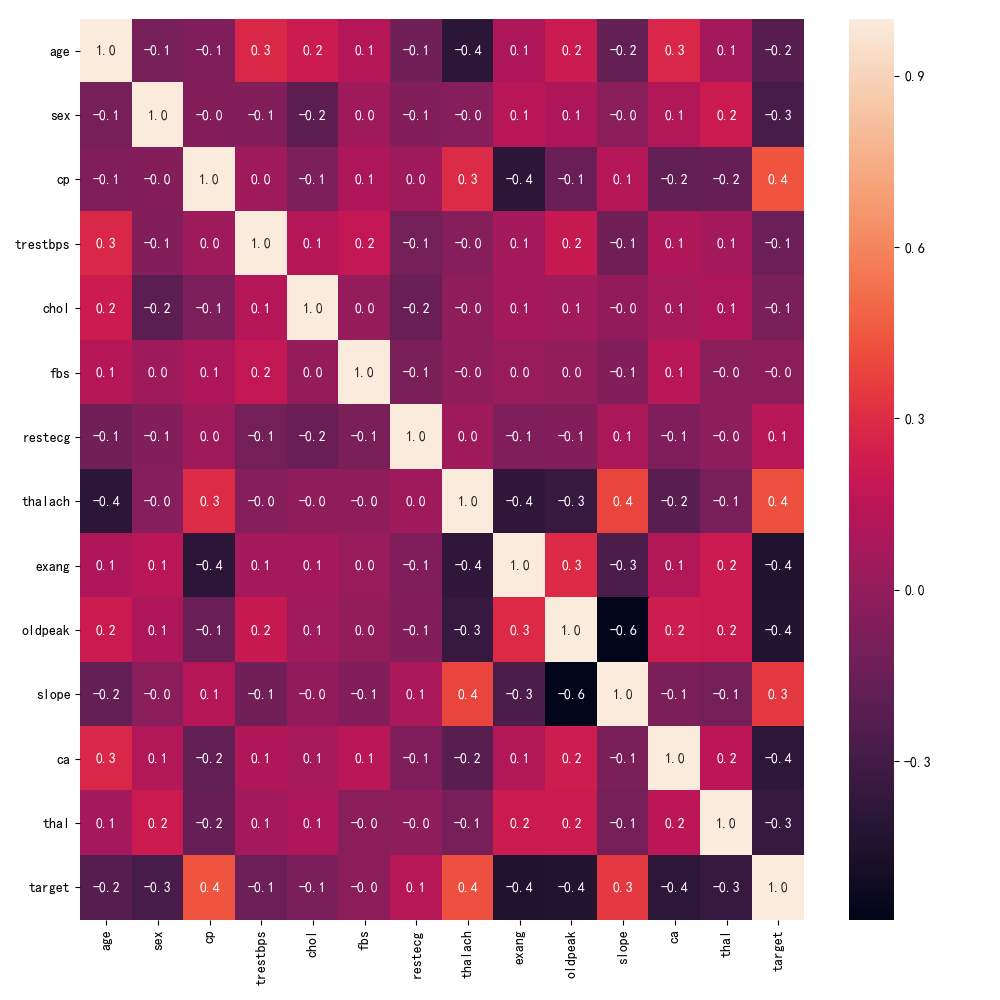
上图中显示了各个特征之间的相关系数,最高的为1.0,越接近1.0则表明相关程度越高。可以通过相关系数矩阵直观的看出哪两个变量之间的相关程度高,可以初步筛选一部分特征,从而达到更好的建模效果。本图中最高的相关系数只达到0.4。
特征随年龄变化的趋势图:
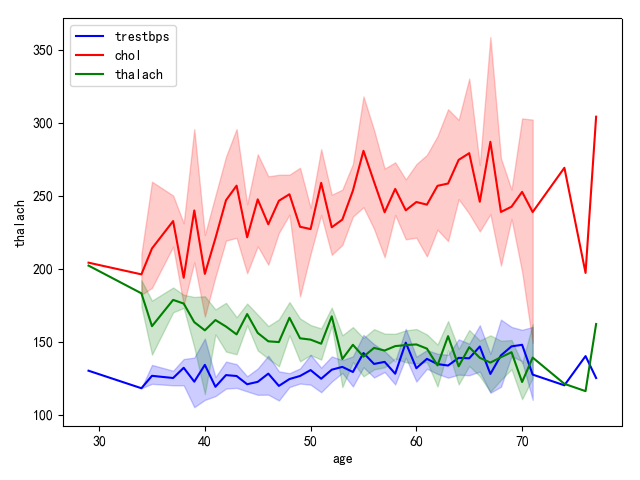
该图中可以看到threstbps有微小的上升趋势,而tahlach的绿色曲线有下降趋势,红色曲线趋势不明显但可看出chol的数据波动很大。
三、模型的建立与预测
3.1.模型介绍:logistic regression
本数据集目的是根据已有的特征进行预测该个体是否有心脏病,当预测值y为1值代表有心脏病,0则为无心脏病,由此可以看出此问题属于一个二分类问题。已知特征向量X,求在X条件下,y为1以及0两个概率值。
\[\begin{equation} P(Y=1\vert{x})=\frac{e^{(\omega\cdot{x}+b)}}{1+e^{(\omega\cdot{x}+b)}} \end{equation}\] \[\begin{equation} P(Y=0\vert{x})=\frac{1}{1+e^{(\omega\cdot{x}}+b)} \end{equation}\]其中x是n维向量,对应于数据集中的n维特征。Y为输出,Y的取值为0或1。b为偏置项,w是x的权重。
上述公式可以进一步简化为:
\[\begin{equation} P(Y=1\vert{x})=\frac{e^{(\omega\cdot{x})}}{1+e^{(\omega\cdot{x})}} \end{equation}\] \[\begin{equation} P(Y=0\vert{x})=\frac{1}{1+e^{(\omega\cdot{x}+b)}} \end{equation}\]其中将偏置项b放入了x中,由此x写为$x={(x^{(1)},x^{(2)},…,x^{(n)},1)}^T$,同时x的权重也更改为$\omega={(\omega^{(1)}, \omega^{(2)}, \underbrace{\ldots}_{\rm ldots},\omega^{(n)}, 1)}^T$ ,通过上述公式,分别求出${P(Y=1\vert{x})}$以及$P{(Y=0\vert{x})}$。
接下来对两个概率值求对数,得到对数几率:
\[\begin{equation} {\log{\frac{P(Y=1\vert{x})}{1-P(Y=1\vert{x})}}=\omega\cdot{x}} \end{equation}\]由上述公式可知输出Y=1的对数几率时输入x的线性函数。接下来用极大似然估计确定权重ω的值。
设:
\[\begin{equation} P(Y=1\vert{x})=\pi(x), P(Y=0\vert{x})=1-\pi(x) \end{equation}\]则似然函数为:
\[\begin{equation} \prod_{i=1}^N{[\pi(x_i)]}^{y_i}{[1-\pi(x_i)]}^{1-y_i} \end{equation}\]化简后的对数似然函数为:
\[\begin{equation} L(\omega)=\sum_{i=1}^N{[y_i(\omega\cdot{x_i})-\log(1+e^{(\omega\cdot{x_i})})]} \end{equation}\]对逻辑回归的代价函数引入正则项 $\sum_{j=1}^n{\omega_j^2}$ ,可得引入正则项后的代价函数:
\[\begin{equation} J(\omega)=-\frac{1}{n}\sum_{i=1}{N}{[y_i(\omega\cdot{x_i})-\log(1+e^{(\omega\cdot{x_i})})]}+\lambda\sum_{j=1}^n{\omega_j^2} \end{equation}\]代价函数取最小值时即使参数w的最大似然估计值,可以用梯度下降法进行求解代价函数的最小值,对ω求导:
\[\begin{equation} \frac{\partial{J(\omega)}}{\partial{\omega}}=-\frac{1}{n}\sum_{i=1}^N{(y_i-\frac{exp(\omega\cdot{x_i})}{1+e^{(\omega\cdot{x_i})})}x_i+\frac{\lambda}{n}\omega_j} \end{equation}\]由此可以得到ω的更新公式:
\[\begin{equation} \omega_j:=\omega_j-\alpha\frac{1}{n}\sum_{i=1}{n}(\pi(x_i)-y_i)x_i^j-\frac{\lambda}{n}\omega_j \end{equation}\]通过上述公式,进行多次迭代,每次迭代都向梯度方向下降,直到找到最优值,即求解到全局最小值,则可得到对应ω的值,假设J(ω)取最小值时ω为\bar{ω}, 则学习到的逻辑回归模型为:
最终学习到的模型为:
\[\begin{equation} P(Y=1\vert{x})=\frac{e^{(\bar{\omega}\cdot{x})}}{1+e^{(\bar{\omega}\cdot{x})}} \end{equation}\] \[\begin{equation} P(Y=0\vert{x})=\frac{1}{1+e^{(\bar{\omega}\cdot{x})}} \end{equation}\]通过上述公式,进行多次迭代,每次迭代向梯度方向下降,直到逐渐收敛得到最优值。
LR较为显著的优点有:1、适合需要得到一个分类概率的场景。2)计算代价不高,容易理解实现。LR在时间和内存需求上相当高效。他可以应用于分布式数据,用较少的资源处理大型数据。3)LR对于数据中小噪声的鲁棒性很好,并且不会受到轻微的多重共线性的特别影响。缺点有:1)易欠拟合,分类精度不高。2)数据特征有缺失或者特征空间很大时表现效果并不好。
3.2.结果分析:
首先将数据分成训练集与测试集,利用逻辑回归对训练集进行训练,将得到的模型对测试集进行预测。下表为逻辑回归的模型评价结果:
模型准确率:
| Accuracy rate | Logistic TRAIN score | Logistic TEST score |
| 0.881578947368421 | 0.8237885462555066 | 0.881578947368421 |
由上表可知模型的准确率达到0.88,训练模型时的损失率为0.82,测试时的准确率为0.88。
将在测试集上的预测结果与真是结果用图显示:
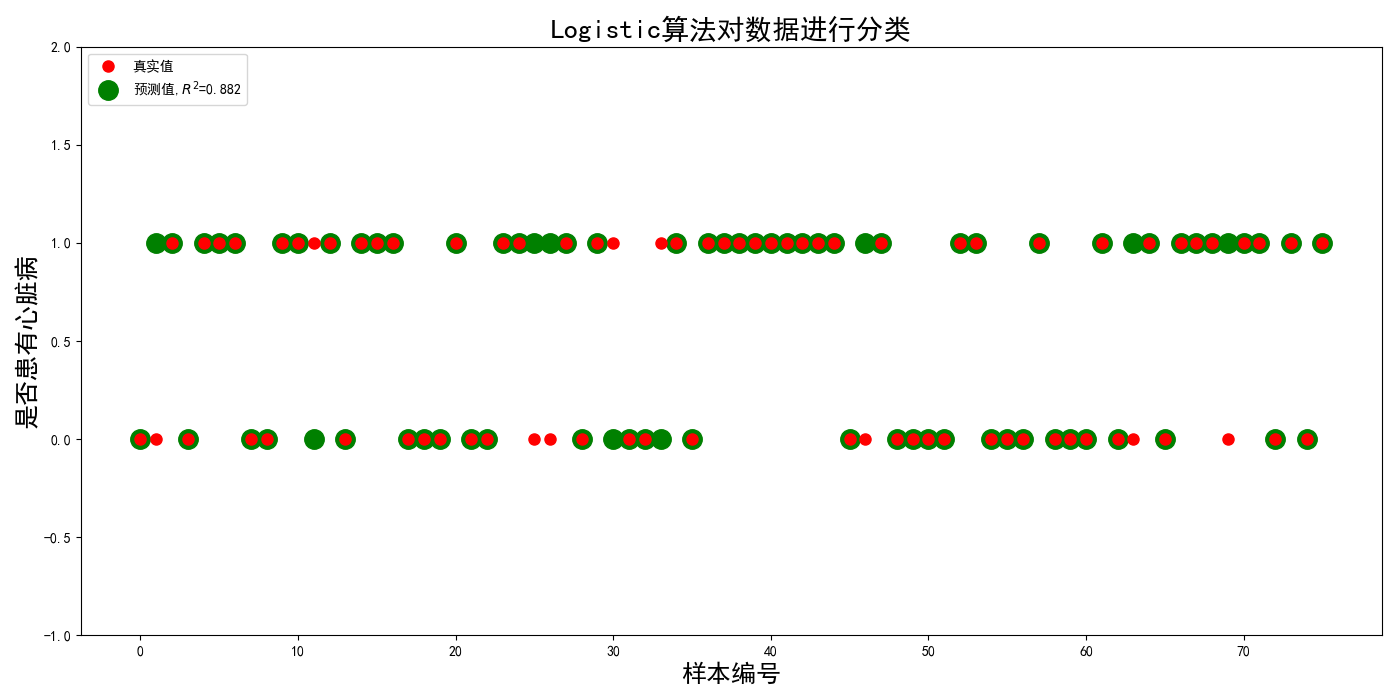
其中红色点表示真实值,绿色点表示预测值。预测准确的就是两点重合的点,预测不准的就是红点或者绿点。
对上述预测值进行构建混淆矩阵
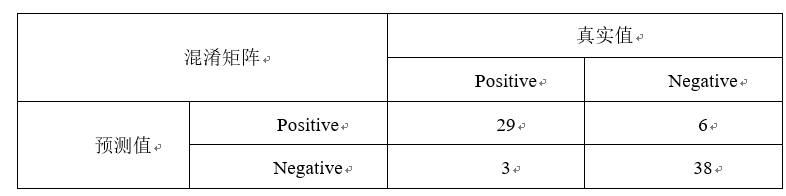
混淆矩阵热力图:
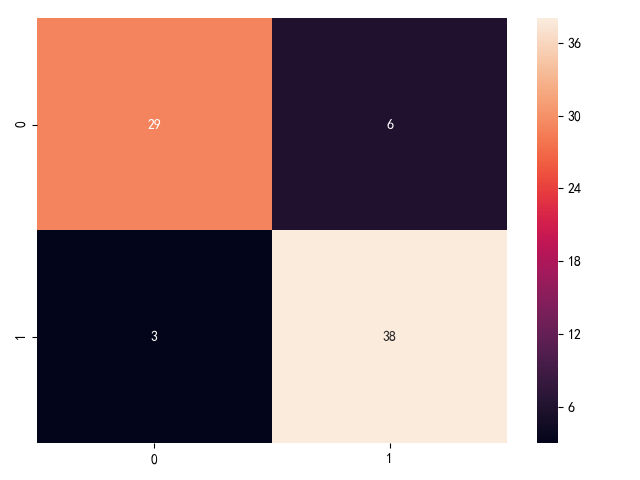
根据混淆矩阵可得到ROC曲线:
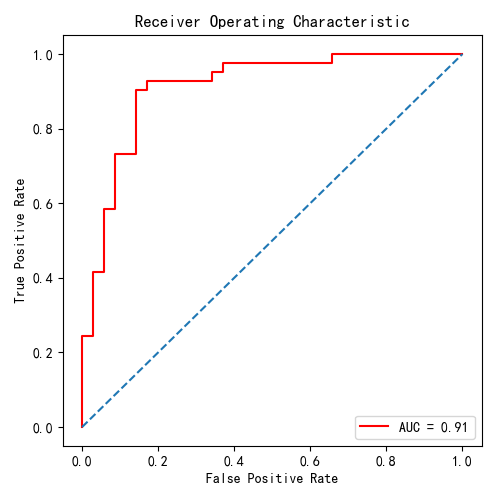
模型最终得出的ω的值如下:
| $ω^{(0)}$ | $ω^{(1)}$ | $ω^{(2)}$ | $ω^{(3)}$ | $ω^{(4)}$ | $ω^{(5)}$ | $ω^{(6)}$ | $ω^{(7)}$ | $ω^{(8)}$ | $ω^{(9)}$ | $ω^{(10)}$ | $ω^{(11)}$ | $ω^{(12)}$ | $ω^{(13)}$ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.19846052 | -0.07412803 | -0.17507829 | 0.23462174 | -0.04428467 | -0.02670934 | 0.0057053 | 0.06717553 | 0.16350515 | -0.21104233 | -0.20351492 | 0.15678816 | -0.21588122 | -0.1846391 |
四、结论:
本文使用逻辑回归的机器学习算法对本数据集的特征进行学习,得到一个准确率为0.88的模型,在一定程度上,此模型得到的预测结果有一定的参考价值。
附录
代码:
from __future__ import print_function
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegressionCV
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model.coordinate_descent import ConvergenceWarning
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.externals import joblib
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
import seaborn as sns
import warnings
# 不显示警告信息
warnings.filterwarnings(action='ignore', category=ConvergenceWarning)
# plt中显示中文的问题
mpl.rcParams["font.sans-serif"] = [u"SimHei"]
mpl.rcParams["axes.unicode_minus"] = False
# 读取文件
data = pd.read_csv('./heart.csv')
# 分出特征和标签
X = data.iloc[:, :-1]
y = data.iloc[:, -1].to_frame()
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
# X_train = (X_train - np.min(X_train)) / (np.max(X_train) - np.min(X_train)).values
# X_test = (X_test - np.min(X_test)) / (np.max(X_test) - np.min(X_test)).values
# 对数据的训练集进行标准化
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
# ===================================================
# 分析特征部分,主要为画图
# ===================================================
sns.pairplot(data, hue='target')
plt.show()
g = sns.jointplot(data.thalach, data.chol, kind="kde", height=7, space=0)
plt.show()
# ===================================================
sns.swarmplot(y="cp", x="restecg", hue="thalach",
palette=["r", "c", "y"], data=data)
plt.show()
# ====================================================
fig = sns.regplot(x="oldpeak", y="thalach", data=data)
plt.title("GRE Score vs CGPA")
plt.show()
# ===================================================
data.describe().plot(kind="area", fontsize=27, figsize=(20, 8), table=True, colormap="rainbow")
plt.xlabel('Statistics', )
plt.ylabel('Value')
plt.title("General Statistics of Admissions")
plt.show()
sns.lineplot(x="age", y="trestbps",
data=data, color='b', label='trestbps')
sns.lineplot(x="age", y="chol",
data=data, color='r', label='chol')
sns.lineplot(x="age", y="thalach",
data=data, color='G', label='thalach')
plt.legend(loc=2)
plt.show()
# =========================
plt.figure(figsize=(20,25))
i = 0
for item in data.columns:
i += 1
plt.subplot(5, 3, i)
sns.distplot(data[item], rug=True, rug_kws={"color": "b"},kde=True,
kde_kws={"color": "blue", "lw": 5, "label": "KDE"},
hist_kws={"histtype": "step", "linewidth": 3,"alpha": 1, "color": "blue"},label="{0}".format(item))
# sns.distplot(admission_v1[item], kde=True,label="{0}".format(item))
plt.show()
# ==============================
for i,col in enumerate(data.columns):
plt.subplot(5,3,i+1)
plt.scatter(np.arange(1,304),data[col].values.tolist())
plt.title(col)
fig, ax = plt.gcf(), plt.gca()
fig.set_size_inches(10, 10)
plt.tight_layout()
plt.show()
# ==============================
# 逻辑回归的参数设定
parameters = [
{
'penalty': ['l1', 'l2'],
'C': [0.1, 0.4, 0.5],
'random_state': [0]
},
]
# lr = LogisticRegression(C=0.1, penalty='l1', random_state=0)
# lr.fit(X_train, y_train)
# ===========================================================================
# 构建并训练模型
# ===========================================================================
def plot_roc_(false_positive_rate, true_positive_rate, roc_auc):
"""
:param false_positive_rate:
:param true_positive_rate:
:param roc_auc:
:return: 画roc曲线
"""
plt.figure(figsize=(5, 5))
plt.title('Receiver Operating Characteristic')
plt.plot(false_positive_rate, true_positive_rate, color='red', label='AUC = %0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
def plot_feature_importances(gbm):
"""
:param gbm:
:return: 画出特征图
"""
n_features = X_train.shape[1]
plt.barh(range(n_features), gbm.feature_importances_, align='center')
plt.yticks(np.arange(n_features), X_train.columns)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plt.ylim(-1, n_features)
lr = LogisticRegressionCV(multi_class="ovr", fit_intercept=True, Cs=np.logspace(-2, 2, 20), cv=2, penalty="l2",
solver="lbfgs", tol=0.01)
re = lr.fit(X_train, y_train)
# 模型效果获取
r = re.score(X_train, y_train)
print("R值(准确率):", r)
print("参数:", re.coef_)
print("截距:", re.intercept_)
print("稀疏化特征比率:%.2f%%" % (np.mean(lr.coef_.ravel() == 0) * 100))
print("=========sigmoid函数转化的值,即:概率p=========")
print(re.predict_proba(X_test)) # sigmoid函数转化的值,即:概率p
# 模型的保存与持久化
joblib.dump(ss, "logistic_ss.model") # 将标准化模型保存
joblib.dump(lr, "logistic_lr.model") # 将训练后的线性模型保存
joblib.load("logistic_ss.model") # 加载模型,会保存该model文件
joblib.load("logistic_lr.model")
# 预测
X_test = ss.transform(X_test) # 数据标准化
Y_predict = lr.predict(X_test) # 预测
# 画图对预测值和实际值进行比较
x = range(len(X_test))
plt.figure(figsize=(14, 7), facecolor="w")
plt.ylim(-1, 2)
plt.plot(x, y_test, "ro", markersize=8, zorder=3, label=u"真实值")
plt.plot(x, Y_predict, "go", markersize=14, zorder=2, label=u"预测值,$R^2$=%.3f" % lr.score(X_test, y_test))
plt.legend(loc="upper left")
plt.xlabel(u"样本编号", fontsize=18)
plt.ylabel(u"是否患有心脏病", fontsize=18)
plt.title(u"Logistic算法对数据进行分类", fontsize=20)
plt.savefig("Logistic算法对数据进行分类.png")
plt.show()
print("=============Y_test==============")
print(np.array(y_test).ravel())
print("============Y_predict============")
print(Y_predict)
y_pred = re.predict(X_test)
y_proba = re.predict_proba(X_test)
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_proba[:, 1])
roc_auc = auc(false_positive_rate, true_positive_rate)
plot_roc_(false_positive_rate, true_positive_rate, roc_auc)
# 查看模型性能
# print('Hata Oranı :',r2_score(y_test,y_pred))
print('Accurancy Oranı :', accuracy_score(y_test, y_pred))
print("Logistic TRAIN score with ", format(re.score(X_train, y_train)))
print("Logistic TEST score with ", format(re.score(X_test, y_test)))
print()
cm = confusion_matrix(y_test, y_pred)
print(cm)
sns.heatmap(cm, annot=True)
plt.show()
print('CoEf:\n')
print(re.coef_)
print('Intercept_\n')
print(re.intercept_)
print('Proba:\n')
print(re.predict_log_proba)